I got a dataframe with three columns and almost 800.000 rows. I want to plot a line plot where the x axis is DateTime and the Y is Value. The problem is, I want to do a different line for EACH code (there are 6 different codes) in the same plot.Each code has NOT the same length, but that does not matter. At the end, I wanna have a plot with 6 different lines where x axis is DATETIME and Y axis is value. I tried many things but I can not plot it.
Here is a sample of my dataframe
import pandas as pd
# intialise data of lists.
data = {'Code':['AABB', 'AABC', 'AABB', 'AABC','AABD', 'AABC', 'AABB', 'AABC'],
'Value':[1, 1, 2, 2,1,3,3,4],
'Datetime': [2022-03-29,2022-03-29,2022-03-30,2022-03-30,2022-03-30,2022-03-31,
2022-03-31,2022-03-31]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
print(df)
I tried this but it plots something that does not make any sense
plt.plot(df["DateTime"], df["value"],linewidth=2.0,color='b',alpha=0.5,marker='o')
CodePudding user response:
Your data
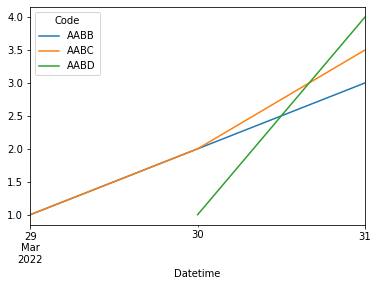
There is a duplicate record, as mentioned by @claudio. There are two rows for AABC:2022/3/31:3 and AABC:2022/3/31:4. So, in such cases, I have taken the average of the two value (3.5 in this case). Also, there is only one entry for AABD. Need two points for a line. So, I have added another entry at the end. Also, the column Datetime has been changed from string to type datetime using the pandas function pd.to_datetime()
The method
You can use the pivot_table() to change the data you have provided to a format that can be converted to line plot. Here, I have used the datetime to be the index, each of the unique Code to be a column (so that each column can be converted to a separate line) and the values as values. Note that I have used aggfunc='mean' to handle the cases of duplicate entry. This will take the mean if there are multiple datapoints. Once the pivot_table is created, that can be plotted as line plot using pandas plot.
Code
import pandas as pd
# intialise data of lists.
data = {'Code':['AABB', 'AABC', 'AABB', 'AABC','AABD', 'AABC', 'AABB', 'AABC', 'AABD'],
'Value':[1, 1, 2, 2,1,3,3,4, 4],
'Datetime': ['2022-03-29','2022-03-29','2022-03-30','2022-03-30','2022-03-30','2022-03-31','2022-03-31','2022-03-31','2022-03-31']}
# Create DataFrame
df = pd.DataFrame(data)
df['Datetime'] = pd.to_datetime(df['Datetime'])
df1 = df.pivot_table(index='Datetime', columns='Code', values='Value', aggfunc='mean')
#print the pivoted data
print(df1)
df1.plot()
Output
>>> df1
Code AABB AABC AABD
Datetime
2022-03-29 1.0 1.0 NaN
2022-03-30 2.0 2.0 1.0
2022-03-31 3.0 3.5 NaN