I have to select a column out of two columns which has more data or values in it using PySpark and keep it in my DataFrame.
For example, we have two columns A and B:
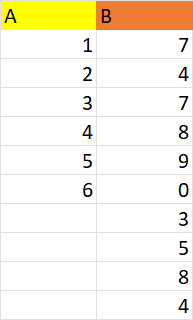
In example, the column B has more values so I will keep it in my DF for transformations. Similarly, I would take A, if A had more values. I think we can do it using if else conditions, but I'm not able to get the correct logic.
CodePudding user response:
You could first aggregate the columns (count the values in each). This way you will get just 1 row which you could extract as dictionary using .head().asDict(). Then use Python's max(your_dict, key=your_dict.get) to get the dict's key having the max value (i.e. the name of the column which has maximum number of values). Then just select this column.
Example input:
from pyspark.sql import functions as F
df = spark.createDataFrame([(1, 7), (2, 4), (3, 7), (None, 8), (None, 4)], ['A', 'B'])
df.show()
# ---- ---
# | A| B|
# ---- ---
# | 1| 7|
# | 2| 4|
# | 3| 7|
# |null| 8|
# |null| 4|
# ---- ---
Script:
val_cnt = df.agg(*[F.count(c).alias(c) for c in {'A', 'B'}]).head().asDict()
max_key = max(val_cnt, key=val_cnt.get)
df.select(max_key).show()
# ---
# | B|
# ---
# | 7|
# | 4|
# | 7|
# | 8|
# | 4|
# ---
CodePudding user response:
Create a data frame with the data
df = spark.createDataFrame(data=[(1,7),(2,4),(3,7),(4,8),(5,0),(6,0),(None,3),(None,5),(None,8),(None,4)],schema = ['A','B'])Define a condition to check for that
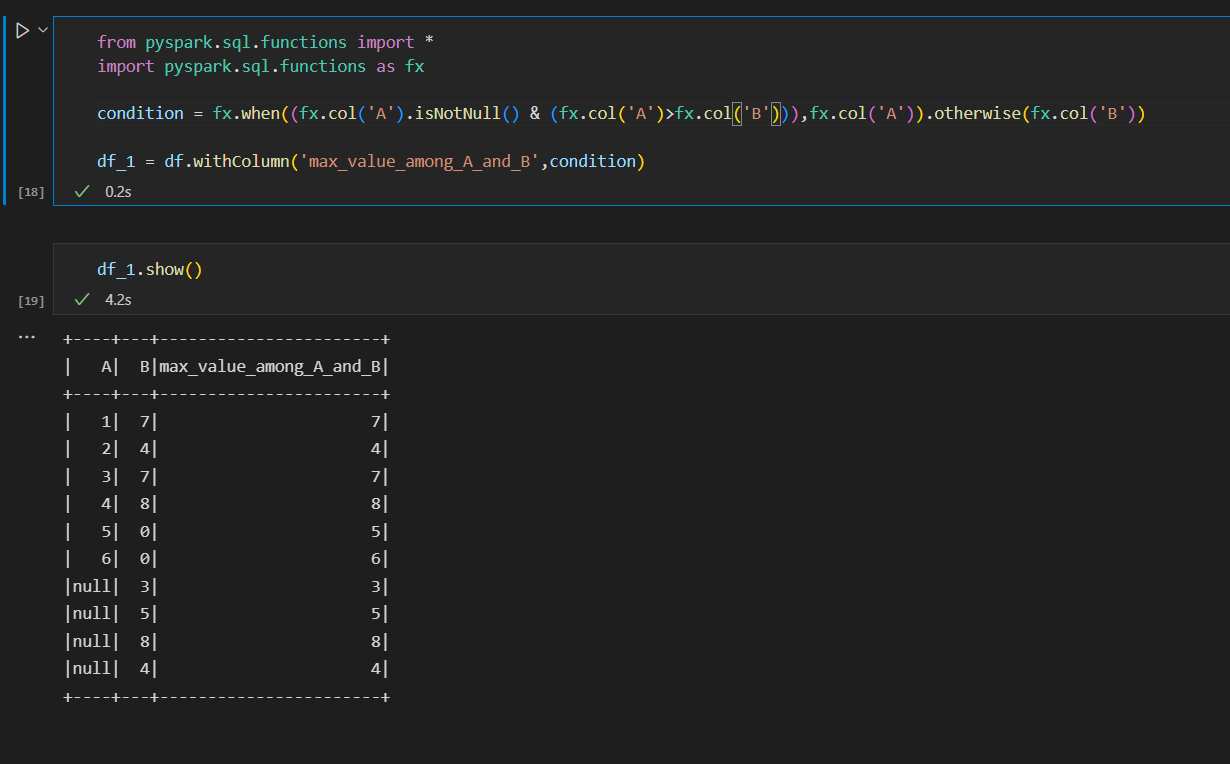
from pyspark.sql.functions import * import pyspark.sql.functions as fx condition = fx.when((fx.col('A').isNotNull() & (fx.col('A')>fx.col('B'))),fx.col('A')).otherwise(fx.col('B')) df_1 = df.withColumn('max_value_among_A_and_B',condition)Print the dataframe
df_1.show()
Please check the below screenshot for details