For the dataset I'm working with, I want to impute null values with medians grouped by country. I have created a grouped table (median_data in the code below), which contains all the median values by country.
I need to do this median calculation and imputation in separate steps since the end goal is to create an object with 'fit' and 'transform' methods, so that I can calculate medians based only on the train data, and impute to the test data.
Here's dummy data I'm working with:
data = [['A', 10, 20, np.nan, np.nan, 50, 30], ['A', 2, 1, 5, np.nan, 34, 35], ['A', 13, 212, 3, 6, np.nan, 37],
['B', 120, 230, 53, np.nan, 63, 23], ['B', 22, 115, 15, 61, 4, 15], ['B', np.nan, 22, 12, np.nan, np.nan, 31],
['C', 105, 120, np.nan, 22, 520, 3], ['C', 26, 11, 15, np.nan, 34, 3], ['C', 13, np.nan, 13, 234, np.nan, 10],
['D', 101, 220, 654, 143, 634, 123], ['D', 32, 21, 61, 24, np.nan, 32], ['D', 11, 72, 23, np.nan, 534, 30]
]
df = pd.DataFrame(data, columns=['Country','col1','col2','col3','col4','col5','col6'])
median_data = df.groupby('Country').median().reset_index()
Currently not using an object, just trying to figure out how to do it. Using loops isn't working. I tried different iterations, here's where I'm at right now:
df_new = df.copy()
for country in median_data.Country:
country_data = median_data[median_data.Country == country].copy()
for col in median_data.columns[2:]:
df_new[col] = df_new[col].fillna(country_data[col])
The dataset, df:
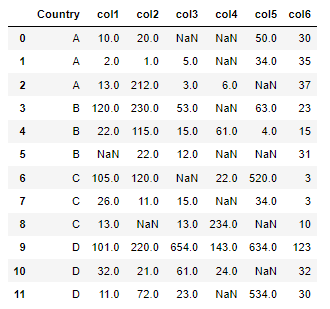
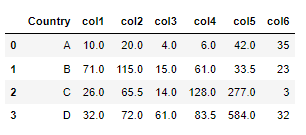
The table with medians grouped by 'Country':
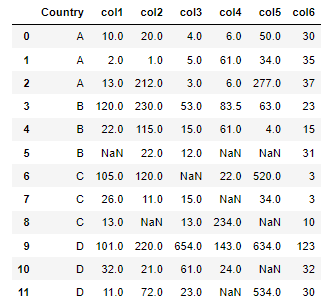
Result from the code above (clearly incorrect). As an example, col4 for Country A should be [6, 6, 6], but the values I get are [6, 61, 6]:
Is there a way to separately calculate median values and impute them? Efficiency is not my primary concern, but an efficient solution would obviously be preferred.
CodePudding user response:
Use DataFrame.update with GroupBy.transform with median:
df.update(df.groupby('Country').transform('median'), overwrite=False)
print (df)
Country col1 col2 col3 col4 col5 col6
0 A 10.0 20.0 4.0 6.0 50.0 30
1 A 2.0 1.0 5.0 6.0 34.0 35
2 A 13.0 212.0 3.0 6.0 42.0 37
3 B 120.0 230.0 53.0 61.0 63.0 23
4 B 22.0 115.0 15.0 61.0 4.0 15
5 B 71.0 22.0 12.0 61.0 33.5 31
6 C 105.0 120.0 14.0 22.0 520.0 3
7 C 26.0 11.0 15.0 128.0 34.0 3
8 C 13.0 65.5 13.0 234.0 277.0 10
9 D 101.0 220.0 654.0 143.0 634.0 123
10 D 32.0 21.0 61.0 24.0 584.0 32
11 D 11.0 72.0 23.0 83.5 534.0 30
Details:
print (df.groupby('Country').transform('median'))
col1 col2 col3 col4 col5 col6
0 10.0 20.0 4.0 6.0 42.0 35
1 10.0 20.0 4.0 6.0 42.0 35
2 10.0 20.0 4.0 6.0 42.0 35
3 71.0 115.0 15.0 61.0 33.5 23
4 71.0 115.0 15.0 61.0 33.5 23
5 71.0 115.0 15.0 61.0 33.5 23
6 26.0 65.5 14.0 128.0 277.0 3
7 26.0 65.5 14.0 128.0 277.0 3
8 26.0 65.5 14.0 128.0 277.0 3
9 32.0 72.0 61.0 83.5 584.0 32
10 32.0 72.0 61.0 83.5 584.0 32
11 32.0 72.0 61.0 83.5 584.0 32
Alternative solution with DataFrame.combine_first:
df1 = df.combine_first(df.groupby('Country').transform('median'))
print (df1)
Country col1 col2 col3 col4 col5 col6
0 A 10.0 20.0 4.0 6.0 50.0 30
1 A 2.0 1.0 5.0 6.0 34.0 35
2 A 13.0 212.0 3.0 6.0 42.0 37
3 B 120.0 230.0 53.0 61.0 63.0 23
4 B 22.0 115.0 15.0 61.0 4.0 15
5 B 71.0 22.0 12.0 61.0 33.5 31
6 C 105.0 120.0 14.0 22.0 520.0 3
7 C 26.0 11.0 15.0 128.0 34.0 3
8 C 13.0 65.5 13.0 234.0 277.0 10
9 D 101.0 220.0 654.0 143.0 634.0 123
10 D 32.0 21.0 61.0 24.0 584.0 32
11 D 11.0 72.0 23.0 83.5 534.0 30