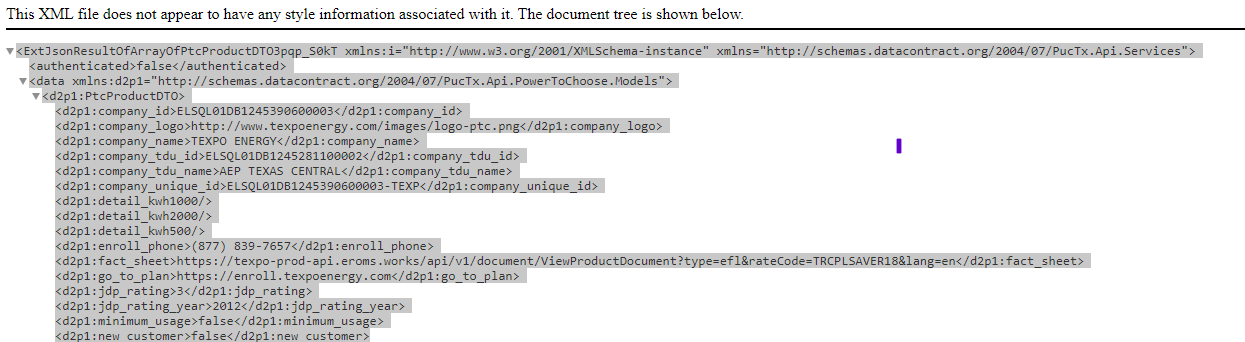
I'm very new to Python and am attempting my first web scraping project. I'm attempting to extract the data following a tag within a XML data source. I've attached an image of the data I'm working with. My issue is that, it seems like no matter what tag I try to extract I constantly return no results. I am able to return the entire data source so I know the connection is not the issue.
My ultimate goal is to loop through all of the data and return the data following a particular tag. I think if I can understand why I'm unable to print a singular particular tag I should be able to figure out how to loop through all of the data. I've looked through similar posts but I think the tree in my set of data is particularly troublesome (that and my inexperience).
My Code:
from bs4 import BeautifulSoup
import requests
#Assign URL to scrape
URL = "http://api.powertochoose.org/api/PowerToChoose/plans?zip_code=78364"
#Fetch the raw HTML Data
Data = requests.get(URL)
Soup = BeautifulSoup(Data.text, "html.parser")
tags = Soup.find_all('fact_sheet')
print (tags)
CodePudding user response:
Try to check the response of your example first, it is JSON not XML so no BeautifulSoup needed here, simply iterate the data list to pick your fact_sheets:
for plan in Data.json()['data']:
print(plan['fact_sheet'])
Out:
https://rates.cleanskyenergy.com:8443/rates/DownloadDoc?path=a70e9298-5537-481a-985c-c7a005b2e4f3.html&id_plan=223344
https://texpo-prod-api.eroms.works/api/v1/document/ViewProductDocument?type=efl&rateCode=SRCPLF24PTC&lang=en
https://www.txu.com/Handlers/PDFGenerator.ashx?comProdId=TCXSIMVL1212AR&lang=en&formType=EnergyFactsLabel&custClass=3&tdsp=AEPTCC
https://signup.myvaluepower.com/Home/EFL?productId=32653&Promo=16410
https://docs.cloud.flagshippower.com/EFL?term=36&duns=007924772&product=galleon&lang=en&code=FPSPTC2
...
CodePudding user response:
As you've already realized by now, you're getting the data as json, so doing something like:
fact_sheet_links = [d['fact_sheet'] for d in Data.json()['data']]
would get you the data you want.
But also, if you'd prefer to work with the xml, you can add headers to the request:
Data = requests.get(URL, headers={ 'Accept': 'application/xml' })
and get an xml response. When I did this, Soup.find_all('fact_sheet') still did not work (although I've seen this method used in some tutorials, so it might be a version problem - and it might still work for you), but it did work when I used find_all with lambda:
tags = Soup.find_all(lambda t: 'fact_sheet' in t.name)
and the results after altering your code looked like this. That just gives you the tags though, so if you want a list of the contents instead, one way would be to use list comprehension:
{kind=link}
fact_sheet_links = [t.text for t in tags]
so that you get them like this.
{kind=link}