I have gotten stuck in trying to subset my data. I am dealing with unvoting.csv and am currently trying to group in by years 50-59, 60-69, etc., and at the same time sort it into PctAgreeUS (to see how it changes over time). Are there any suggestions or baseline ways to code the data to create a new vector that holds this information (sorry if the terms I used are wrong still getting familiar with it)
CodePudding user response:
I think you can use the dplyr package to do so. Import the library and than use the dplyr::filter function to filter and dplyr::arrange() for order the data reg specific columns.
CodePudding user response:
We do not have your csv file, so it is impossible to know what the specific columns in your data frame are. Luckily, there is an R package called "unvotes" that contains the same information. Using that, you could carry out your analysis like this:
library(unvotes)
library(tidyverse)
result <- un_votes %>%
left_join(un_roll_calls, by = "rcid") %>%
group_by(rcid) %>%
filter("United States" %in% country, .preserve = TRUE) %>%
mutate(US_agree = vote == vote[country == "United States"],
total = n() - 1) %>%
filter(country != "United States") %>%
summarize(date = first(date),
US_agree = sum(US_agree),
total = first(total)) %>%
mutate(decade = lubridate::year(date) %/% 10 * 10) %>%
group_by(decade) %>%
summarize(US_agree = sum(US_agree),
total = sum(total),
prop = prop.test(US_agree, total)$estimate,
lower = prop.test(US_agree, total)$conf.int[1],
upper = prop.test(US_agree, total)$conf.int[2]) %>%
mutate(decade = factor(paste(decade, decade 9, sep = "-")))
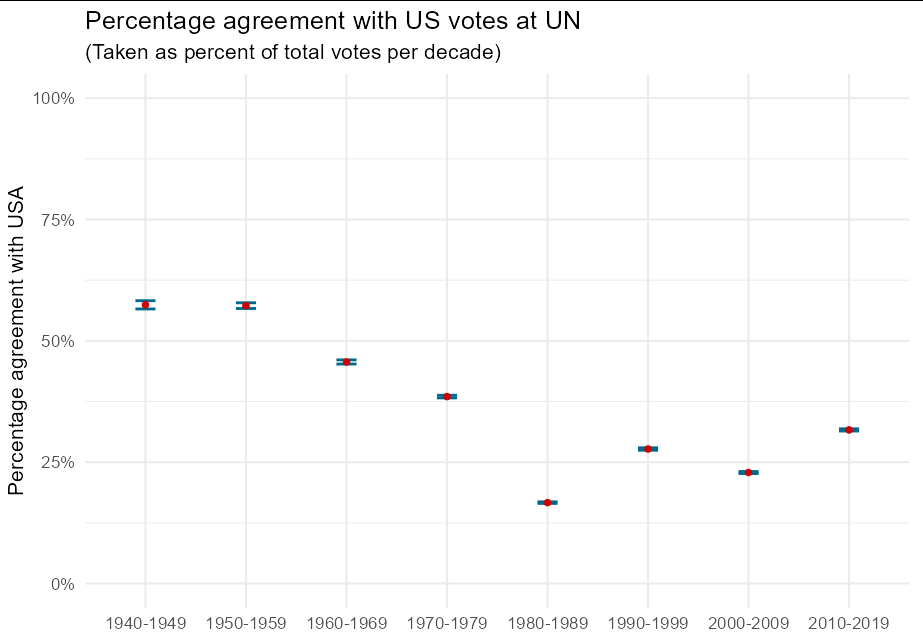
This gives the gollowing result (note we have proportions instead of percentages)
result
#> # A tibble: 8 x 6
#> decade US_agree total prop lower upper
#> <fct> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 1940-1949 7515 13087 0.574 0.566 0.583
#> 2 1950-1959 15610 27265 0.573 0.567 0.578
#> 3 1960-1969 23831 52205 0.456 0.452 0.461
#> 4 1970-1979 47515 123367 0.385 0.382 0.388
#> 5 1980-1989 33753 202498 0.167 0.165 0.168
#> 6 1990-1999 33482 120811 0.277 0.275 0.280
#> 7 2000-2009 35768 156401 0.229 0.227 0.231
#> 8 2010-2019 51337 162199 0.317 0.314 0.319
This allows, for example, a plot of percentages by decade with 95% confidence intervals:
ggplot(result, aes(decade, prop))
geom_errorbar(aes(ymin = lower, ymax = upper), width = 0.2, size = 1,
color = "deepskyblue4")
geom_point(size = 2, col = "red3")
theme_minimal(base_size = 16)
scale_y_continuous(limits = 0:1, labels = scales::percent,
name = "Percentage agreement with USA")
labs(x = NULL, title = "Percentage agreement with US votes at UN",
subtitle = "(Taken as percent of total votes per decade)")
Created on 2022-10-14 with reprex v2.0.2