I am looking to resample and interpolate between each row of a data.frame in a fast way. I don't mind working with data.table or other data structures if necessary. Here is a reproducible example :
df <- data.frame(x = c(0, 2, 10),
y = c(10, 12, 0))
Desired output : a function f(df, n), where n is the number of interpolation values that would lead to :
df_int <- f(df, 1)
# That would produce :
# df_int <- data.frame(x = c(0, 1, 2, 6, 10),
# y = c(10, 11, 12, 6, 0))
df_int <- f(df, 3)
# That would produce :
# df_int <- data.frame(x = c(0, 0.5, 1, 1.5, 2, 4, 6, 8, 10),
# y = c(10, 10.5, 11, 11.5, 12, 9, 6, 3, 0))
Some solutions were proposed using approx but that doesn't work in my case.
CodePudding user response:
Without consideration of speed
interpolate_vector <- function(x, n) {
Reduce(function(x, tail_x) {
c(head(x, -1), seq(tail(x, 1), tail_x[1], length.out = n 2))
}, init = x[1], x = tail(x, -1))
}
f <- function(df, n) {
as.data.frame(lapply(df, interpolate_vector, n))
}
f(df, 1)
x y
1 0 10
2 1 11
3 2 12
4 6 6
5 10 0
f(df, 3)
x y
1 0.0 10.0
2 0.5 10.5
3 1.0 11.0
4 1.5 11.5
5 2.0 12.0
6 4.0 9.0
7 6.0 6.0
8 8.0 3.0
9 10.0 0.0
Without Reduce and growing vectors:
interpolate_vector_2 <- function(x, n) {
res <- numeric(length = (length(x)-1) * (n 1) 1)
for (i in head(seq_along(x), -1)) {
res[(i (i-1)*n) : (i i*n 1)] <-
seq(x[i], x[i 1], length.out = n 2)
}
res
}
f_2 <- function(df, n) {
as.data.frame(lapply(df, interpolate_vector_2, n))
}
Benchmark template (including @Maël's answers):
res <- bench::press(
rows = c(1e2, 1e3),
n = c(1, 3, 10),
{
df <- data.frame(
x = runif(rows),
y = runif(rows)
)
bench::mark(
zoo = f_3(df, n),
loop = f_2(df, n),
reduce = f(df, n),
approx = f_4(df, n)
)
}
)
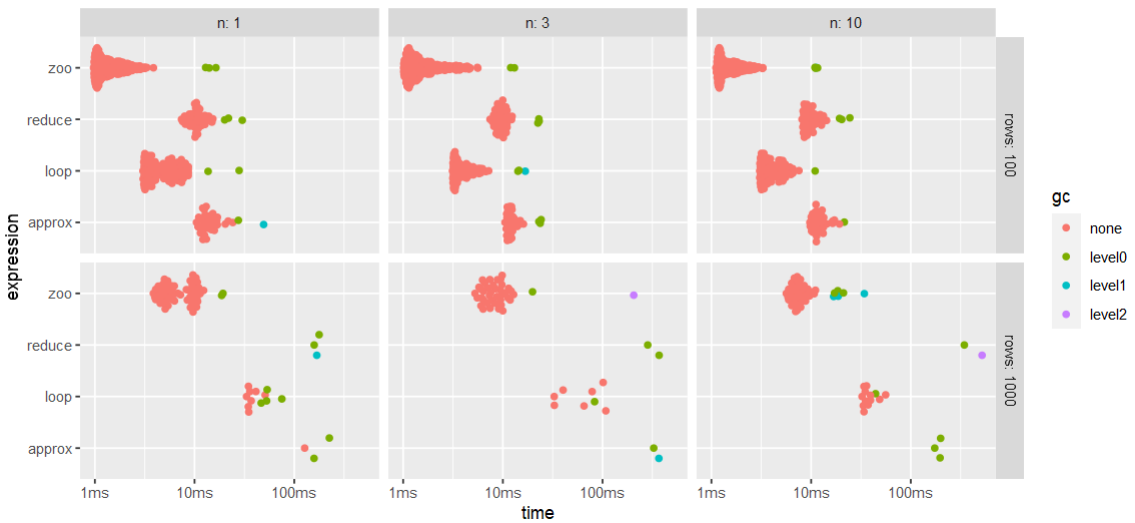
CodePudding user response:
Using approx:
interp <- function(x, n){
v = c()
for(i in seq(length(x) - 1)) {
tmp = approx(c(x[i], x[i 1]), n = 2 n)$y
v = c(v, tmp)
}
v[!duplicated(v)]
}
f <- function(df, n) as.data.frame(lapply(df, interp, n))
examples
f(df, 1)
# x y
# 1 0 10
# 2 1 11
# 3 2 12
# 4 6 6
# 5 10 0
f(df, 3)
# x y
# 1 0.0 10.0
# 2 0.5 10.5
# 3 1.0 11.0
# 4 1.5 11.5
# 5 2.0 12.0
# 6 4.0 9.0
# 7 6.0 6.0
# 8 8.0 3.0
# 9 10.0 0.0
CodePudding user response:
Another possibility with zoo::na.approx. The idea is to create a vector with n NA between the elements of the vectors, and then use na.approx. This solution is supposedly the fastest (see benchmark).
library(zoo)
interp <- function(v, n){
na_vec <- c(sapply(v, \(x) c(x, rep(NA, n))))[1:((length(v) - 1) * (n 1) 1)]
zoo::na.approx(na_vec)
}
f <- function(df, n) as.data.frame(lapply(df, interp, n))
examples
f(df, 1)
# x y
# 1 0 10
# 2 1 11
# 3 2 12
# 4 6 6
# 5 10 0
f(df, 3)
# x y
# 1 0.0 10.0
# 2 0.5 10.5
# 3 1.0 11.0
# 4 1.5 11.5
# 5 2.0 12.0
# 6 4.0 9.0
# 7 6.0 6.0
# 8 8.0 3.0
# 9 10.0 0.0