I am doing some Logistics Regression homework.
I just wonder if in any case, the evaluation metrics for the test set are a bit better than the training set (like my results below)? And if yes, what gap is allowed?
Below is my evaluation result for the test set and training set, given that both sets are extracted from the same dataset.
EVALUATION METRICS FOR Test Dataset:
Confusion Matrix:
Predicted Negative Predicted Positive
Actual Negative 82 20
Actual Positive 10 93
Accuracy = 0.8536585365853658
Precision = 0.8230088495575221
Recall = 0.9029126213592233
F1 score = 0.8380535530381049
EVALUATION METRICS FOR Training Dataset:
Confusion Matrix:
Predicted Negative Predicted Positive
Actual Negative 279 70
Actual Positive 44 324
Accuracy = 0.8410041841004184
Precision = 0.8223350253807107
Recall = 0.8804347826086957
F1 score = 0.8315648343229267
CodePudding user response:
Usually this is not the case, but it is not impossible. If you randomly split your data into a test and a training set, the test data can fit better to your model than the training data in some cases. Imagine the extreme case below, where your data consists of values with different levels of noise added to it. If the test data points are the ones with less noise, they will fit better to the model. However, such a split into test and training data is very unlikely.
If the test score is just slightly above the training score, this is absolutely normal. If by chance, noise not captured by the model is slightly lower in the test data, the test samples will fit better to the model. Actually this a good sign, because it means that you are not over fitting. You may be able to increase overall performance by increasing the degrees of freedom in your model.
If the test score is much higher then the training score, you should check whether the split between test data and training has been done in a reasonable way.
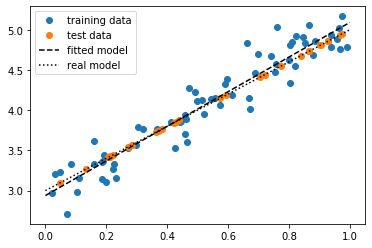
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return 2*x 3
x_test = np.random.rand(30)
x_training = np.random.rand(70)
y_test = f(x_test) 1e-3 * np.random.randn(30)
y_training = f(x_training) 0.2 * np.random.randn(70)
k, d = np.polyfit(x_training, y_training, 1)
x = np.linspace(0, 1)
plt.plot(x_training, y_training, 'o', label='training data')
plt.plot(x_test, y_test, 'o', label='test data')
plt.plot(x, k*x d, 'k--', label='fitted model')
plt.plot(x, f(x), 'k:', label='real model')
plt.legend();
plt.show()