I am new to pandas, and I have a dataframe (which I get after processing) that looks like this: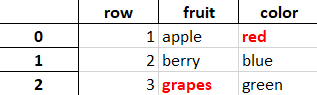
I was unable to find any help/info regarding how can I remove the first column (row_number/ index) to make it like this: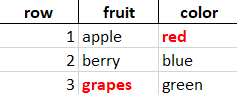
Any help would be appreciated.
Edit: additional question example: 
CodePudding user response:
If I understand everything correctly then your dataframe looks like this:
row fruit color
0 0 apple red
1 1 berry blue
2 2 grapes green
Now if you want to write dataframe to a csv file without first column indexing then use dataframe.to_csv("file.csv", index=False) so that the file.csv file will look like this:
row,fruit,color
0,apple,red
1,berry,blue
2,grapes,green
And to remove header or first row use header=False to dataframe.to_csv("file.csv", index=False, header=False). Then your file.csv will look like:
0,apple,red
1,berry,blue
2,grapes,green
Hope this helps!!! And keep up the work toward learning Pandas.
CodePudding user response:
You can turn 'row' into your index, and remove the existing ("autonumbered" so to speak) index: df.set_index("row", inplace=True)
You can see all the options for set_index in the pandas docs:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.set_index.html