Hoping to sort (below left) by sector but distribute evenly (below right):
| Name | Sector. | Name. | Sector |
|---|---|---|---|
| A | 1 | A | 1 |
| B | 1 | E | 2 |
| C | 1 | H | 3 |
| D | 4 | D | 4 |
| E | 2 | B | 1 |
| F | 2 | F | 2 |
| G | 2 | J | 3 |
| H | 3 | I | 4 |
| I | 4 | C | 1 |
| J | 3 | G | 2 |
Real data is 70 rows with 4 sectors.
I've worked around it manually but would love to figure out how to do it with a formula in excel.
Here's a more complete (and hopefully more accurate) idea - the carouselOrder is the column I'd like to generate via a formula.
| guestID | guestSector | carouselOrder |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 5 |
| 3 | 1 | 9 |
| 4 | 1 | 13 |
| 5 | 2 | 2 |
| 6 | 2 | 6 |
| 7 | 2 | 10 |
| 8 | 2 | 14 |
| 9 | 3 | 3 |
| 10 | 3 | 7 |
| 11 | 3 | 11 |
| 12 | 2 | 18 |
| 13 | 1 | 17 |
| 14 | 1 | 20 |
| 15 | 1 | 23 |
| 16 | 2 | 21 |
| 17 | 2 | 24 |
| 18 | 2 | 27 |
| 19 | 1 | 26 |
| 20 | 1 | 29 |
| 21 | 1 | 30 |
| 22 | 1 | 31 |
| 23 | 3 | 15 |
| 24 | 3 | 19 |
| 25 | 3 | 22 |
| 26 | 3 | 25 |
| 27 | 3 | 28 |
| 28 | 1 | 32 |
| 29 | 4 | 4 |
| 30 | 4 | 8 |
| 31 | 4 | 12 |
| 32 | 4 | 16 |
CodePudding user response:
Let's try the following approach that doesn't require to create a helper column. I would like to explain first the logic to build the recurrence, then the excel formula that builds such recurrence.
If we sort the input data Name and Sector. by Sector. in ascending order, the new positions of the Name values (letters) can be calculated as follow (Table 1):
| Name | Sector.Sorted | Position |
|---|---|---|
| A | 1 | 1 4*0=1 |
| B | 1 | 1 4*1=5 |
| C | 1 | 1 4*2=9 |
| E | 2 | 2 4*0=2 |
| F | 2 | 2 4*1=6 |
| G | 2 | 2*4*2=10 |
| H | 3 | 3 4*0=3 |
| J | 3 | 3 4*1=7 |
| D | 4 | 4 4*0=4 |
| I | 4 | 4 4*1=8 |
The new positions of Name (letters) follows this pattern (Formula 1):
position = Sector.Sorted groupSize * factor
where groupSize is 4 in our case and factor counts how many times the same Sector.Sorted value is repeated, starting from 0. Think about Sector.Sorted as groups, where each set of repeated values represents a group: 1,2,3 and 4.
If we are able to build the Position values we can sort Name, based on the new positions via SORTBY(array, by_array1) function. Check 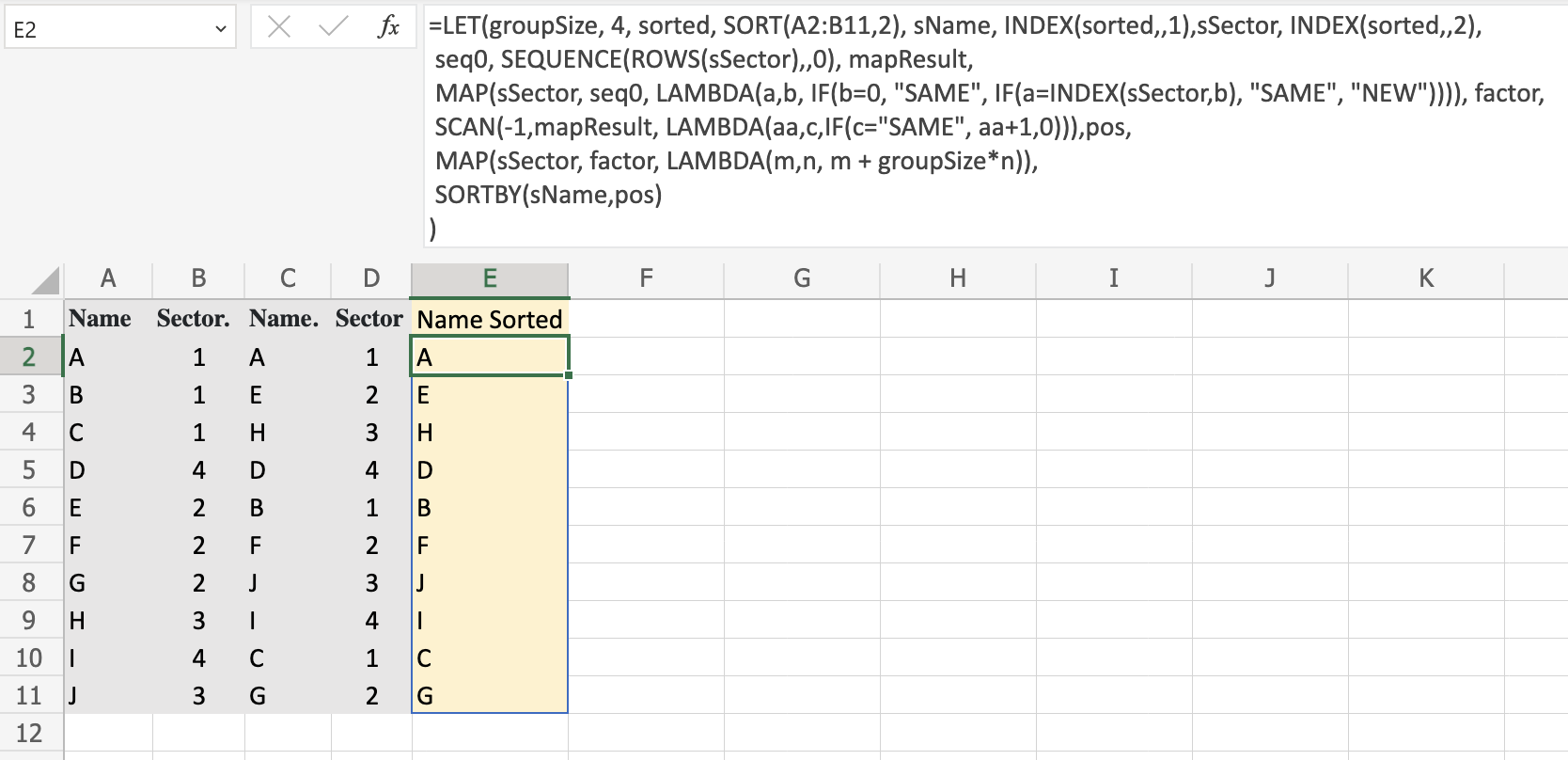
Explanation
The name sorted represents the input data sorted by Sector. in ascending order, i.e.: SORT(A2:B11,2). The names sName and sSector represents each column of sorted.
To identify each group we need the following sequence (seq0) starting from 0, i.e. SEQUENCE(ROWS(sSector),,0).
Now we need to identify when a new group starts. We use MAP function for that and the result is represented by the name mapResult:
MAP(sSector, seq0, LAMBDA(a,b, IF(b=0, "SAME",
IF(a=INDEX(sSector,b), "SAME", "NEW"))))
The logic is the following: If we are at the beginning of the sequence (first value of seq0), then returns SAME otherwise we check current value of sSector (a) against the previous one represented by INDEX(sSector,b) if they are the same, then we are in the same group, otherwise a new group started.
The intermediate result of mapResult is:
| Name | Sector Sorted | mapResult |
|---|---|---|
| A | 1 | SAME |
| B | 1 | SAME |
| C | 1 | SAME |
| E | 2 | NEW |
| F | 2 | SAME |
| G | 2 | SAME |
| H | 3 | NEW |
| J | 3 | SAME |
| D | 4 | NEW |
| I | 4 | SAME |
The first two columns are shown just for illustrative purpose, but mapResult only returns the last column.
Now we just need to create the counter based on every time we find NEW. In order to do that we use SCAN function and the result is stored under the name factor. This value represents the factor we use to multiply by 4 within each group (see Table 1):
SCAN(-1,mapResult, LAMBDA(aa,c,IF(c="SAME", aa 1,0)))
The accumulator starts in -1, because the counter starts with 0. Every time we find SAME, it increments by 1 the previous value. When it finds NEW (not equal to SAME), the accumulator is reset to 0.
Here is the intermediate result of factor:
| Name | Sector Sorted | mapResult | factor |
|---|---|---|---|
| A | 1 | SAME | 0 |
| B | 1 | SAME | 1 |
| C | 1 | SAME | 2 |
| E | 2 | NEW | 0 |
| F | 2 | SAME | 1 |
| G | 2 | SAME | 2 |
| H | 3 | NEW | 0 |
| J | 3 | SAME | 1 |
| D | 4 | NEW | 0 |
| I | 4 | SAME | 1 |
The first three columns are shown for illustrative purpose.
Now we have all the elements to build our pattern for the new positions represented with the name pos:
MAP(sSector, factor, LAMBDA(m,n, m groupSize*n))
where m represents each element of Sector.Sorted and factor the previous calculated values. As you can see the formula in Excel represents the generic formula (Formula 1 see above). The intermediate result will be:
| Name | Sector Sorted | mapResult | factor | pos |
|---|---|---|---|---|
| A | 1 | SAME | 0 | 1 |
| B | 1 | SAME | 1 | 5 |
| C | 1 | SAME | 2 | 9 |
| E | 2 | NEW | 0 | 2 |
| F | 2 | SAME | 1 | 6 |
| G | 2 | SAME | 2 | 10 |
| H | 3 | NEW | 0 | 3 |
| J | 3 | SAME | 1 | 7 |
| D | 4 | NEW | 0 | 4 |
| I | 4 | SAME | 1 | 8 |
The previous columns are shown just for illustrative purpose. Now we have the new positions, so we are ready to sort based on the new positions for Name via:
SORTBY(sName,pos)
CodePudding user response:
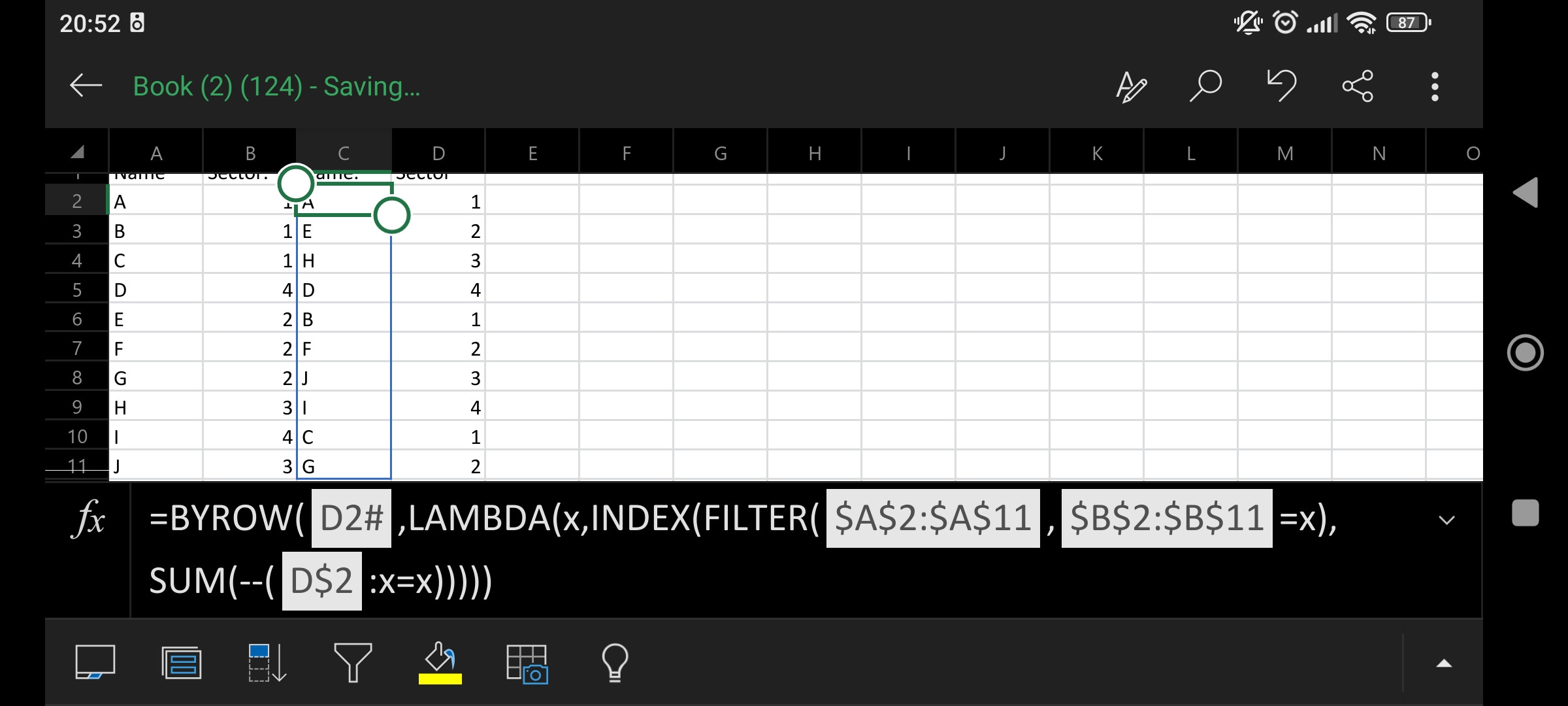
When using Office 365 you can use the following in D2: =MOD(SEQUENCE(COUNTA(A2:A11),,0),4) 1
This create the repetitive counter of the sectors 1 to 4 to the total count of rows in your data.
In C2 use the following:
=BYROW(D2#,LAMBDA(x,
INDEX(
FILTER($A$2:$A$11,$B$2:$B$11=x),
SUM(--(D$2:x=x)))))
This filters the Names that equal the sector of mentioned row and indexes it to show only the result where the row in the filter result equals the count of the same sector (D2#) up to current row.