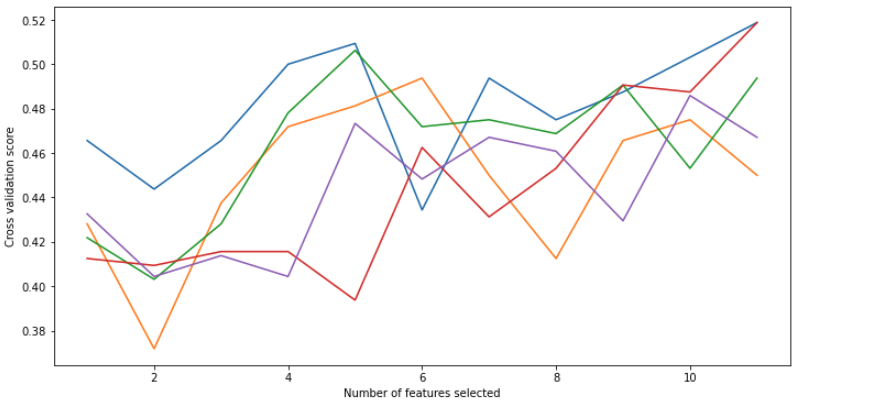
I'm trying to plot the CV score for recursive feature selection for a wine quality data set. I can't work out why my plot ends up splitting out into 5 lines... My expectation is that it will be 1 line showing the change in CV score for a number of selected features.
rfe.grid_scores_ comes out as a list of lists... I've no idea why its doing this. All examples I have seen plotting grid_scores like this show the plot as one line without any indexing of the list...
dataset_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv'
df = pd.read_csv(dataset_url)
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn import preprocessing
from sklearn.preprocessing import MinMaxScaler
# define dataset
x = df.iloc[:, 0:-1]
y = df.quality
# create pipeline
rfe = RFECV(estimator=DecisionTreeClassifier())
model = RandomForestRegressor()
pipeline = Pipeline(steps=[('s',rfe),('m',model)])
pipeline.fit(x,y)
# evaluate model
cv = RepeatedKFold(n_splits=10)
n_scores = cross_val_score(pipeline, x, y, cv=cv, n_jobs=1, error_score='raise', scoring = 'neg_mean_squared_error')
plt.figure(figsize=(12,6))
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score")
plt.plot(range(1, len(rfe.grid_scores_) 1), rfe.grid_scores_)
plt.show()
CodePudding user response:
The reason why your plot splits into 5 lines is because your target variable, y, has 5 distinct values: 3, 4, 5, 6, and 7. These are the quality ratings of the wine. When you use RepeatedStratifiedKFold as your cross-validation strategy, it preserves the proportion of each class in each fold. This means that each fold will have a different mean and variance of the target variable, and therefore a different optimal number of features to select. The RFECV algorithm will try to find the best number of features for each fold, and then average the scores across all folds. This results in a list of lists, where each sublist corresponds to a fold, and each element in the sublist is the score for a given number of features.
To fix this, you can either use a different cross-validation strategy, such as RepeatedKFold, which does not stratify the folds by the target variable, or you can use a different scoring metric, such as neg_mean_squared_error, which is more suitable for regression problems. Alternatively, you can treat your problem as a classification problem, and use a classifier instead of a regressor, and a classification metric, such as accuracy or f1_score.
CodePudding user response:
You're plotting five lines because rfe.grid_scores_ returns an array of (number of features, scores per fold) or (11,5). By 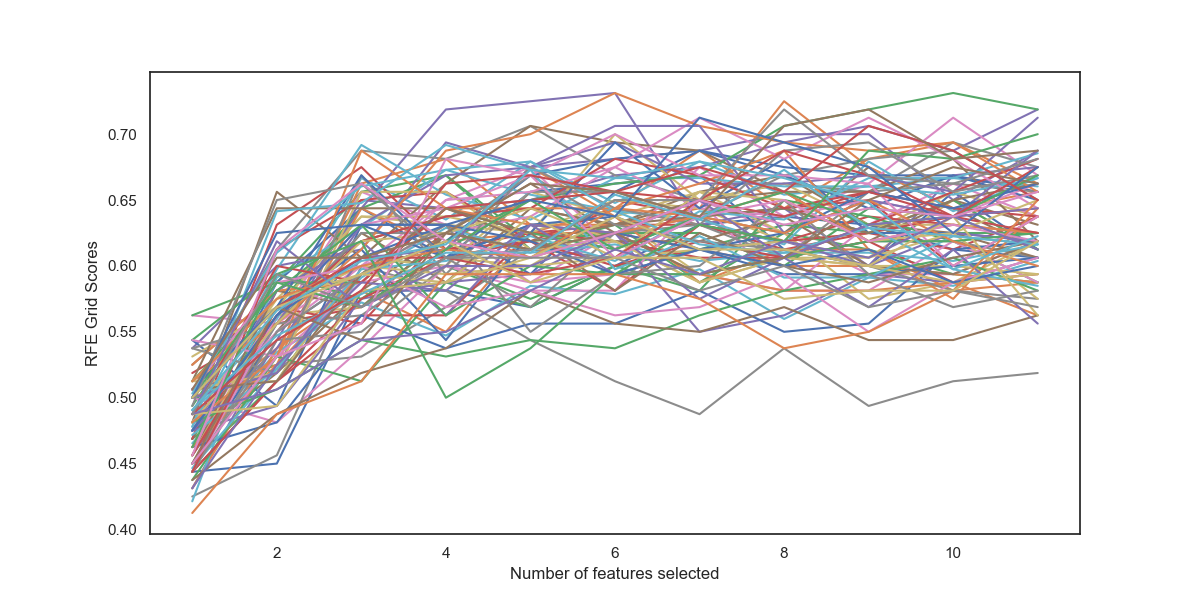
Notice also that these are the grid scores, not your cross-validation scores. You'll need to plot n_scoresto view the actual cross-validation scores.