I'm working on a spreadsheet where data is added in real time by an API. The data from the API is from users who sign up for a newsletter consists of basic data. When data is send from de API, it is added as a new row in the spreadsheet.
Users also have the option to answer additional newsletter questions later, this will also cause the API to add a new row, with additional data that is placed in different columns, but also still show the existing data that was previously known.
To avoid clutter, I want to remove duplicates based on one column and keep the last entry in Google Sheets. Which results in removing the old basic data row and only keeping the row with additional data. To highlight that this is data that is "updated" by the user, I also highlight this row. The data used to mark submissions as duplicates will be based on a user's email address. Since this will remain the same in both cases. [I may have to be careful with uppercase and lowercase letters, where the script doesn't see two emails as duplicates, I don't have an answer for that yet]
Besides this I already have a script in place that adds current time and date to an added row and places it in the first colomn.
For the duplicate issue, I already found a simular question 
My problem is as follows:
Currently some new users that are being added by the API for the first time, are also being highlighted. I suspect this has something to do with the fact that the duplicate deletion also works when the value of the email colomn is empty. However, this is only an assumption given the limited knowledge I have of these matters.
Seen is this example:
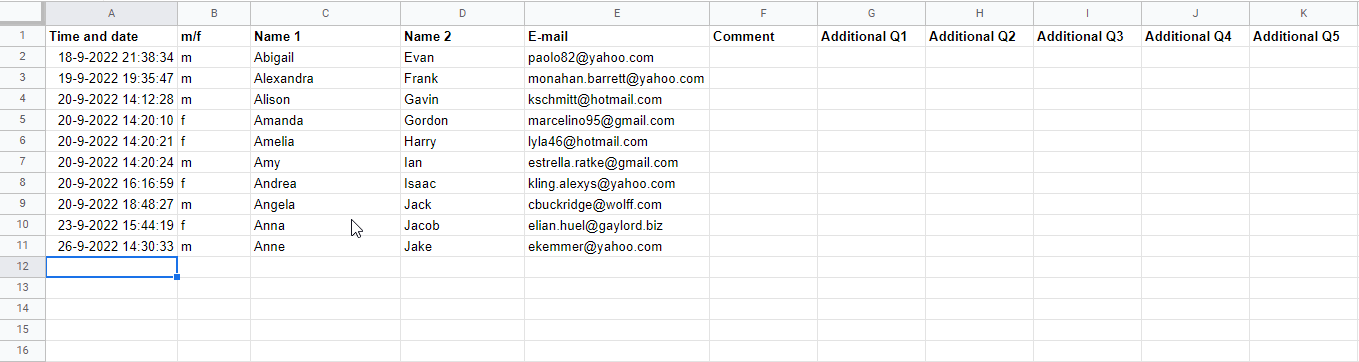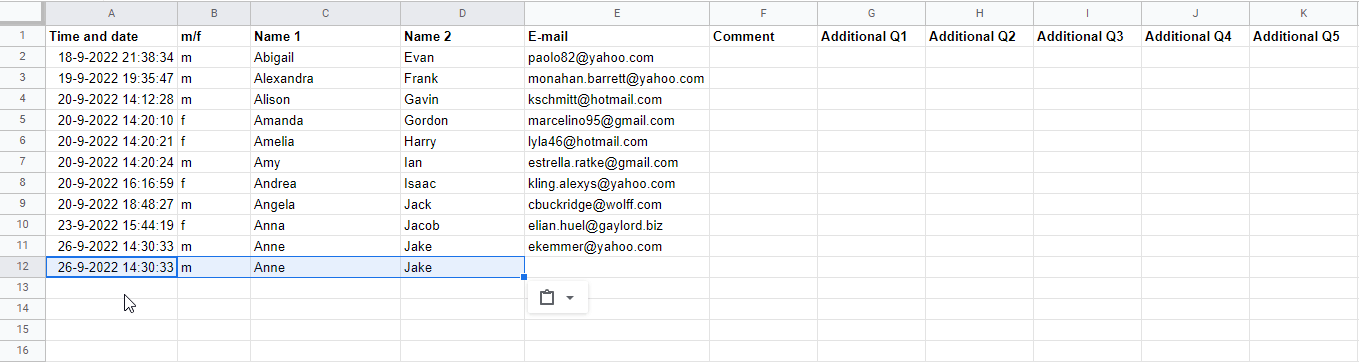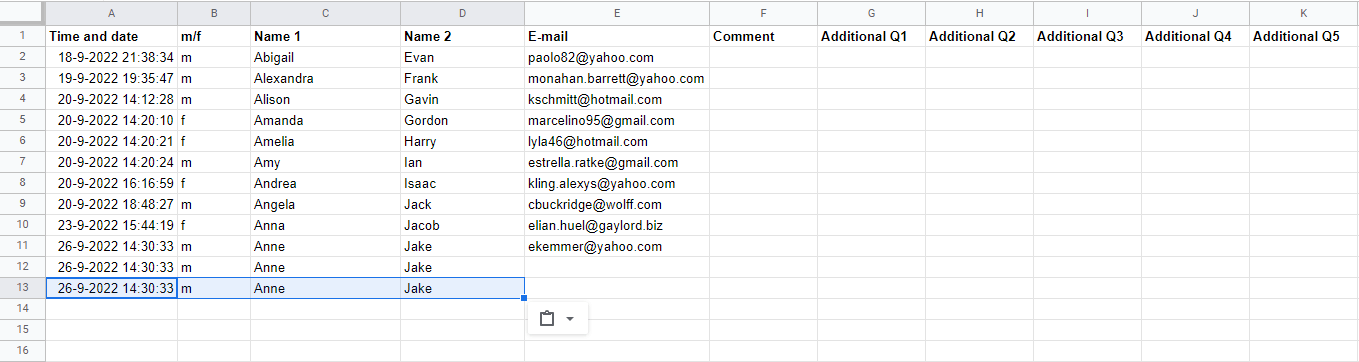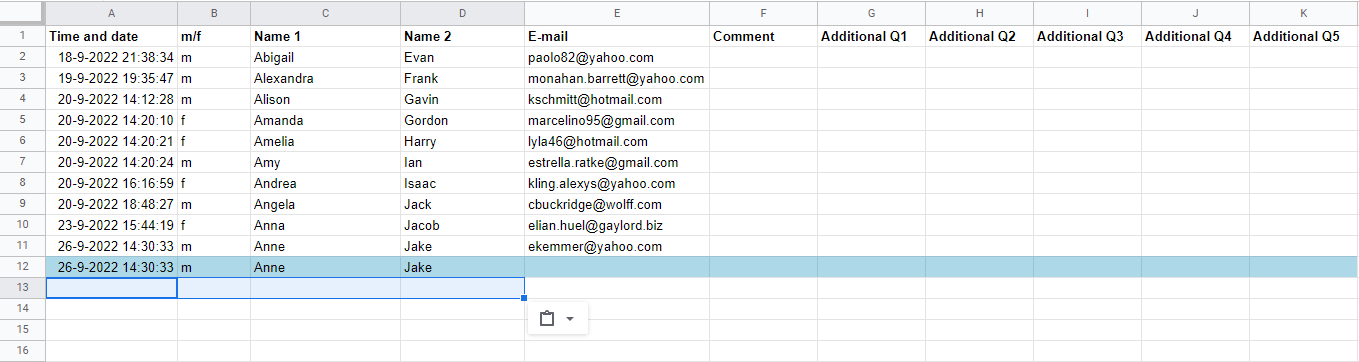
Long story short
I would love for this script to work as I intend it to do, where it only removes duplicates based on a duplicate email adress in colomn E. It would be even better if the duplicate deletion script also ignores capitalization. And lastly that it also ignores blank entries in colomn E.
I tried to use the script Remove duplicates based on one column and keep latest entry in google sheets
And make some addition in this script. Stuff like:
function removeDuplicates() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sh = ss.getSheetByName('Inzendingen');
var dt = sh.getDataRange().getValues();
var uA = [];
for (var i = dt.length - 1; i >= 0; i--) {
if (uA.indexOf(dt[i][4]) == -1 && dt.length !=0 ) {
uA.push(dt[i][4]);
} else {
sh.deleteRow(i 1);
sh.getRange(sh.getLastRow(),1,1,sh.getLastColumn()).setBackground('lightblue');
}
}
}
Where I thought adding && dt.length !=0 would signal to the "if" to only trigger when there's a duplicate and when the value/length is not 0.
CodePudding user response:
If I understand you correctly, the only issue is around these new people with no emails being highlighted. I believe you are on the right track, but you have dt.length != 0, which is looking at the entire array. Instead, you want to just check for the email.
As such, you can use this:
dt[i][4].length != 0
or
dt[i][4] != ""
EDIT: I believe this will give the results you want. Blank emails are ignored, and duplicate emails ignore case.
function removeDuplicates() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sh = ss.getSheetByName('Inzendingen');
var dtAll = sh.getDataRange().getValues();
dt = dtAll.map(function(f){return [f[4].toLowerCase()]});
var uA = [];
for (var i = dt.length - 1; i >= 0; i--) {
if (uA.indexOf(dt[i][0]) == -1) {
uA.push(dt[i][0]);
Logger.log(uA[i]);
} else if (dt[i][0] != ""){
sh.deleteRow(i 1);
sh.getRange(sh.getLastRow(),1,1,sh.getLastColumn()).setBackground('lightblue');
}
}
}