I have this web page:
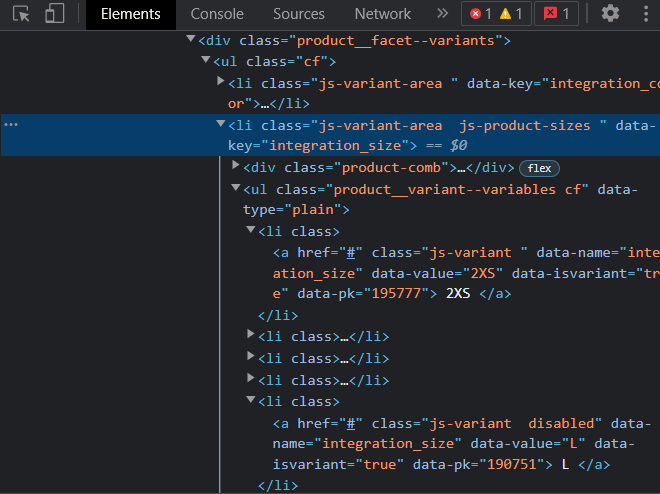
this code has the sizes in it. you can see that some class has: js-variant and some has js-variant disabled
what i want is to select the text where the class is js-variant using web scraping.
I tried doing: response.css('a.js-variant ::text').extract()
but this does not work properly and gives all the values even the ones that has a class disabled in it.
how can I do that?
CodePudding user response:
There is a space in class like this js-variant and we can use xpath to get exact matches.
items = response.xpath("//a[@class='js-variant ']")
for item in items:
item_text = item.css("::text").get().strip()
CodePudding user response:
There are two types of sizes which are active and disabled and they are to be diffrentiated by two class attributes js-variant and js-variant disabled
when you use js-variant then it's found in the both sizes. So the better choice here is xpath expression BUT the following xpath expression selects only the active sizes:
(//*[@])[2]/li//*[@]
As you are using response, assuming that you want to implement it with scrapy.
Example:
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
def start_requests(self):
yield scrapy.Request ('https://tr.uspoloassn.com/erkek-beyaz-polo-yaka-t-shirt-basic-50249146-vr013/',
callback = self.parse
)
def parse(self, response):
yield {'size':[x.get().strip() for x in response.xpath('(//*[@])[2]/li//*[@]/text()')]}
Output:
{'size': ['2XS', 'XS', 'S', 'M']}