I would like to extract everything that comes before a number using regex.
The dataframe below shows an example of what I want to do.
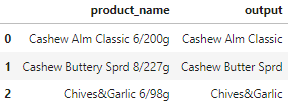
I want to extract everything that comes before the first number in the product_name column. The output column is what I want to get.
Thank you in advance!
product_name = ['Cashew Alm Classic 6/200g', 'Cashew Buttery Sprd 8/227g', 'Chives&Garlic 6/98g']
output = ['Cashew Alm Classic', 'Cashew Butter Sprd', 'Chives&Garlic']
data = pd.DataFrame(list(zip(product_name, output)), columns=['product_name', 'output'])
data
CodePudding user response:
I might use an str.replace approach here:
df["output"] = df["product_name"].str.replace(r'\s \d /\d \w*g$', '', regex=True)
This has a slight advantage over using str.extract in that it doesn't require us assuming what content we want to keep. Rather it just specifies to remove any possible units term appearing at the end of the product name.
Here is a regex demo showing that the replacement logic is working.
CodePudding user response:
df['output2']=df['product_name'].str.extract(r'(.*?)\s(?=\d)')
df
#(.*?) : non-greedy capture everything
# \s: prior to space
# (?=\d) prior to a digit - positive lookahead
product_name output output2
0 Cashew Alm Classic 6/200g Cashew Alm Classic Cashew Alm Classic
1 Cashew Buttery Sprd 8/227g Cashew Butter Sprd Cashew Buttery Sprd
2 Chives&Garlic 6/98g Chives&Garlic Chives&Garlic
CodePudding user response:
Try:
data["output_new"] = data["product_name"].str.extract(r"^(\D )\s ")
print(data)
Prints:
product_name output output_new
0 Cashew Alm Classic 6/200g Cashew Alm Classic Cashew Alm Classic
1 Cashew Buttery Sprd 8/227g Cashew Butter Sprd Cashew Buttery Sprd
2 Chives&Garlic 6/98g Chives&Garlic Chives&Garlic