I have a data file with column names like this (numbers in the name from 1 to 32):

| inlet_left_cell-10<stl-unit=m>-imprint) | inlet_left_cell-11<stl-unit=m>-imprint) | inlet_left_cell-12<stl-unit=m>-imprint) | ------- | inlet_left_cell-9<stl-unit=m>-imprint) |
|---|---|---|---|---|
| data | data | data | data | data |
| data | data | data | data | data |
| .... | .... | ... | ... | .... |
I would like to sort the columns (with data) from left to right in python based on the number in the columns. I need to move a whole column based on the number in the column name.
So xxx-1xxx, xxx-2xx, xxx-3xxx, ...... xxx-32xxx
| inlet_left_cell-1<stl-unit=m>-imprint) | inlet_left_cell-2<stl-unit=m>-imprint) | inlet_left_cell-3<stl-unit=m>-imprint) | ------- | inlet_left_cell-32<stl-unit=m>-imprint) |
|---|---|---|---|---|
| data | data | data | data | data |
| data | data | data | data | data |
| .... | .... | ... | ... | .... |
Is there any way to do this in python ? Thanks.
CodePudding user response:
Here is the solution
# Some random data
data = np.random.randint(1,10, size=(100,32))
# Setting up column names as given in your problem randomly ordered
columns = [f'inlet_left_cell-{x}<stl-unit=m>-imprint)' for x in range(1,33)]
np.random.shuffle(columns)
# Creating the dataframe
df = pd.DataFrame(data, columns=columns)
df.head()
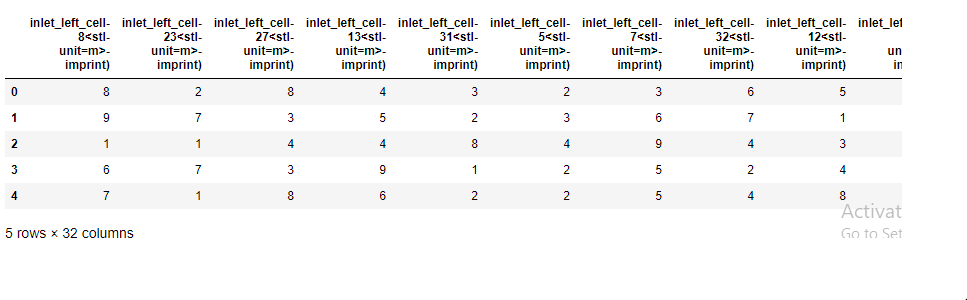
# Sorting the columns in required order
col_nums = [int(x.split('-')[1].split('<')[0]) for x in df.columns]
column_map = dict(zip(col_nums, df.columns))
df = df[[column_map[i] for i in range(1,33)]]
df.head()
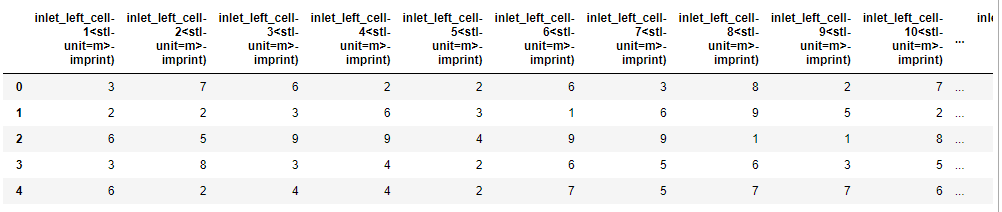
CodePudding user response:
There many ways to do it...I'm just posting simply way.
- Simply extract column names & sort them using
natsort.
Assuming Dataframe name as df..
from natsort import natsorted, ns
dfl=list(df) #used to convert column names to list
dfl=natsorted(dfl, alg=ns.IGNORECASE) # sort based on subtsring numbers
df_sorted= df[dfl] #Re arrange Df
print(df_sorted)
CodePudding user response:
If the column names differ only by this number, try this:
import pandas as pd
data = pd.read_excel("D:\\..\\file_name.xlsx")
data = data.reindex(sorted(data.columns), axis=1)
For example:
data = pd.DataFrame(columns=["inlet_left_cell-23<stl-unit=m>-imprint)", "inlet_left_cell-47<stl-unit=m>-imprint)", "inlet_left_cell-10<stl-unit=m>-imprint)", "inlet_left_cell-12<stl-unit=m>-imprint)"])
print(data)
inlet_left_cell-23<stl-unit=m>-imprint) inlet_left_cell-47<stl-unit=m>-imprint) inlet_left_cell-10<stl-unit=m>-imprint) inlet_left_cell-12<stl-unit=m>-imprint)
After this:
data = data.reindex(sorted(data.columns), axis=1)
print(data)
inlet_left_cell-10<stl-unit=m>-imprint) inlet_left_cell-12<stl-unit=m>-imprint) inlet_left_cell-23<stl-unit=m>-imprint) inlet_left_cell-47<stl-unit=m>-imprint)