I have a data file like that :
[linux]
foo
faafaa
fii
[windows]
faa fii@@
<tag1>fuu</tag1>
foo1234
[osname3]
faa faa
[osname4]
fiifoo
I'm lookin for capture all os name and the content inner each os title. The number of os and the contents are variables and one content can contain all existing caracters. The expected result after the REGEX is something like this :
Match1 :
Groupe1 : 'linux'
Groupe2 : 'foo
faafaa'
Match2 :
Groupe1 : 'windows'
Groupe2 : '
faa fii@@
<tag1>fuu</tag1>
foo1234
'
Match3 :
Groupe1 : 'osname3'
Groupe2 : 'faa faa'
Match4 :
Groupe1 : 'osname4'
Groupe2 : 'fiifoo'
My last try is this REGEX : (?:\[([\S ] )\]\n((?:[\s\S\n])(?!\n\[))*)
But, 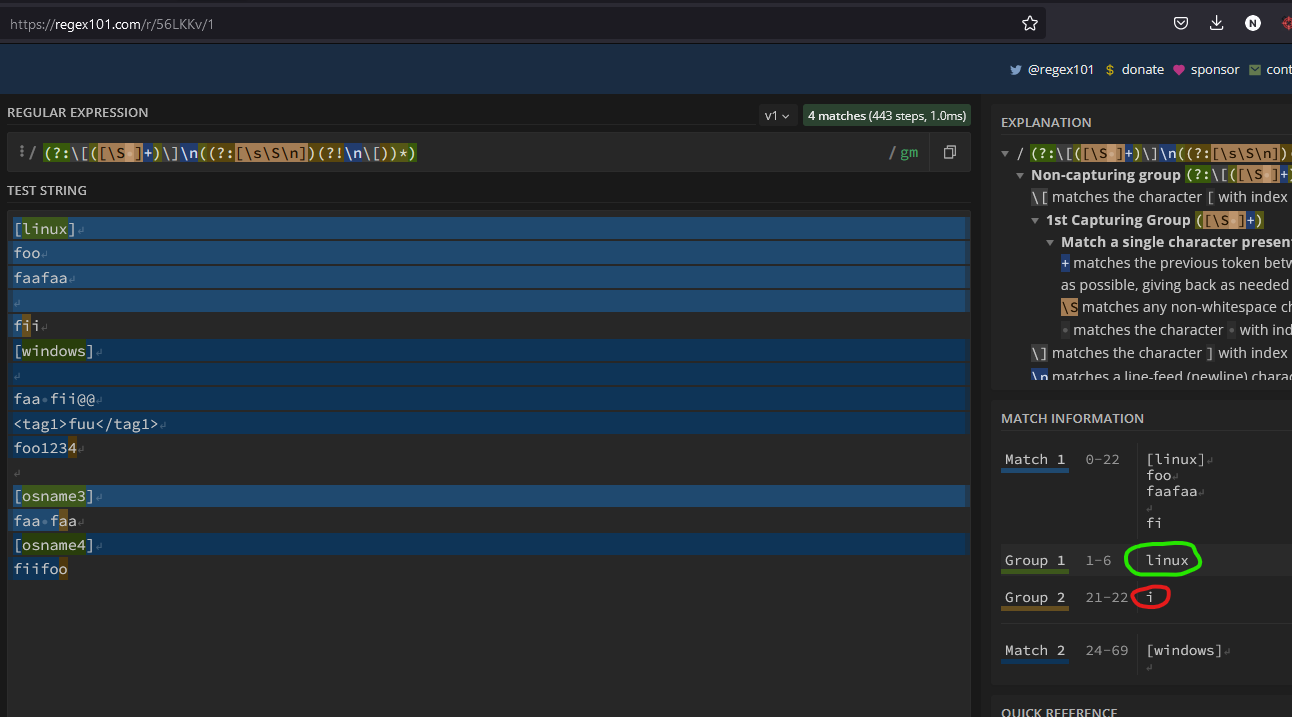
The issue is here : (?:[\s\S\n])(?!\n\[))*
If I translate what I want to do here : "please REGEX, can you capture all caracters ([\s\S\n]) but stop before the pattern (\n\[)" ?
But I don't have what I expected to and I don't understand why...
Lastly, for some reasons, my REGEX needs to be usable with php and javascript
Thanks for any help :)
CodePudding user response:
I doubt that this regex will hold for more complex cases you want to match, but it seems to pass the given input:
const regex = /(?:\[(\w )\])\n((?:[^[]*\n|[^[]))*/gm;
// ^^^^^^^^^^^^ match lines that do not contain '['
// ^^^^^ match inside brackets
However, this input looks like TOML - so in that case, please use a TOML parser instead of regex :)