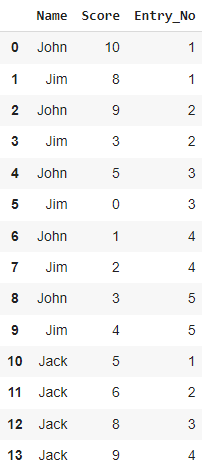
I have the following dataframe containing scores for a competition as well as a column that counts what number entry for each person.
import pandas as pd
df = pd.DataFrame({'Name': ['John', 'Jim', 'John','Jim', 'John','Jim','John','Jim','John','Jim','Jack','Jack','Jack','Jack'],'Score': [10,8,9,3,5,0, 1, 2,3, 4,5,6,8,9]})
df['Entry_No'] = df.groupby(['Name']).cumcount() 1
df
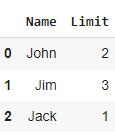
Then I have another table that stores data on the maximum number of entries that each person can have:
df2 = pd.DataFrame({'Name': ['John', 'Jim', 'Jack'],'Limit': [2,3,1]})
df2
I am trying to drop rows from df where the entry number is greater than the Limit according to each person in df2 so that my expected output is this:
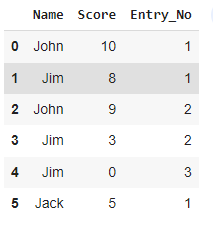
If there are any ideas on how to help me achieve this that would be fantastic! Thanks
CodePudding user response:
You can use pandas.merge to create another dataframe and drop columns by your condition:
df3 = pd.merge(df, df2, on="Name", how="left")
df3[df3["Entry_No"] <= df3["Limit"]][df.columns].reset_index(drop=True)
Name Score Entry_No
0 John 10 1
1 Jim 8 1
2 John 9 2
3 Jim 3 2
4 Jim 0 3
5 Jack 5 1
I used how="left" to keep the order of df and reset_index(drop=True) to reset the index of the resulting dataframe.
CodePudding user response:
You could join the 2 dataframes, and then drop with a condition:
import pandas as pd
df = pd.DataFrame({'Name': ['John', 'Jim', 'John','Jim', 'John','Jim','John','Jim','John','Jim','Jack','Jack','Jack','Jack'],'Score': [10,8,9,3,5,0, 1, 2,3, 4,5,6,8,9]})
df['Entry_No'] = df.groupby(['Name']).cumcount() 1
df2 = pd.DataFrame({'Name': ['John', 'Jim', 'Jack'],'Limit': [2,3,1]})
df2 = df2.set_index('Name')
df = df.join(df2, on='Name')
df.drop(df[df.Entry_No>df.Limit].index, inplace = True)
gives the expected output