I want to extract the pourcentage value with beautifulsoup. I tried to get all value on the page but it returns always 0%.
I want to scrap this value:
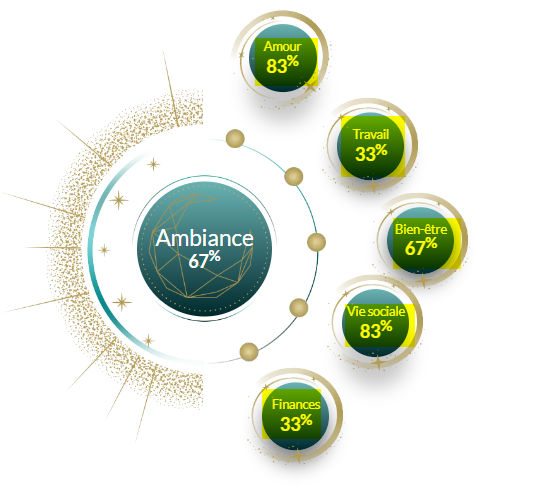
On this web site.
Here is my code to get all the pourcentage value :
import requests
from bs4 import BeautifulSoup
URL = "https://www.horoscope.fr/horoscopes/aujourdhui/scorpion"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
results = soup.find(id="ResultsContainer")
trucs = soup.find_all('strong')
for truc in trucs:
print(truc.text)
And i get this :
0%
0%
0%
0%
0%
0%
15 € les 10 minutes
Gui
Apple cobbler
How can i extract the value ?
CodePudding user response:
Joking aside, here is one way of obtaining horoscope values (you can eventually map them to a percentage for a 1-6 scale):
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
import json
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36'
}
url = 'https://www.horoscope.fr/horoscopes/aujourdhui/scorpion'
r = requests.get(url, headers=headers)
soup = bs(r.text, 'html.parser')
data = json.loads(soup.select_one('script[id="__NEXT_DATA__"]').text)
magic_stuffs = data['props']['pageProps']['initialProps']['horoscope']['overviews']
df = pd.json_normalize(magic_stuffs)
print(df)
Result in terminal:
rating title iconUrl titleColor anchorId
0 5 AMOUR https://cdn.tlmq.fr/mbe/horoscope/rating_5_v1.png #000 love
1 2 TRAVAIL https://cdn.tlmq.fr/mbe/horoscope/rating_2_v1.png #000 career
2 4 BIEN-ÊTRE https://cdn.tlmq.fr/mbe/horoscope/rating_4_v1.png #000 wellbeing
3 5 VIE SOCIALE https://cdn.tlmq.fr/mbe/horoscope/rating_5_v1.png #000 social_life
4 4 AMBIANCE https://cdn.tlmq.fr/mbe/horoscope/rating_4_v1.png #000 mood
5 2 FINANCES https://cdn.tlmq.fr/mbe/horoscope/rating_2_v1.png #000 finances
You can map the integer values to displayed percentages (a 5 rating is an 83%, 2 is 33%, and so on).
Those percentages are displayed dynamically by javascript executed in page, so Requests cannot see them, and bs4 cannot parse them.
Relevant documentation for Requests: https://requests.readthedocs.io/en/latest/
For Pandas: https://pandas.pydata.org/docs/
And for BeautifulSoup: https://beautiful-soup-4.readthedocs.io/en/latest/