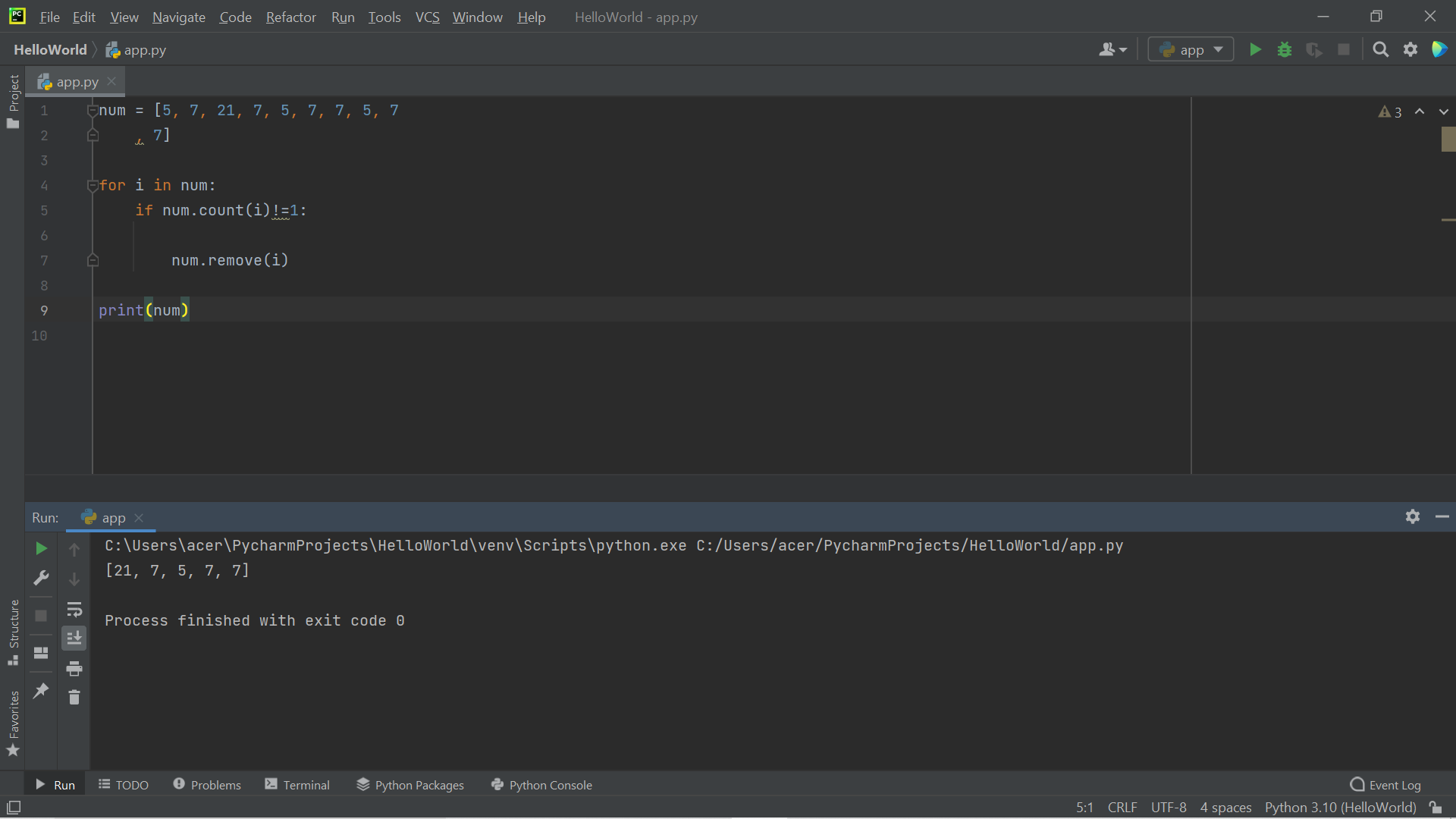
I expected every element to go through the for loop, then the duplicate ones to be removed through the if loop.
num = [5, 7, 21, 7, 5, 7, 7, 5, 7 , 7]
for i in num:
if num.count(i)!=1:
num.remove(i)
print(num)
CodePudding user response:
Since you are reducing the size of array while iterating on it.
for i in num will check for the length of num. After 5 iterations (i=5), the length of num will become 5 and the loop will break.
It's better to always avoid mutating the list you're looping on.
Same result can also be achieved simply by:
num = list(set(num))
CodePudding user response:
list. remove(object) Removes the first item from the list which matches the specified value.
To solve your purpose we can utilize a data structure name set which have property to store multiple items in a single variable.
num = [5, 7, 21, 7, 5, 7, 7, 5, 7 , 7]
print(set(num))
If you want to go with your logic instead of using set data structure checkout this code
num = [5, 7, 21, 7, 5, 7, 7, 5, 7 , 7]
res = []
for i in range(len(num)):
if num.index(num[i])==i:
res.append(num[i])
print(res)
OR
num = [5, 7, 21, 7, 5, 7, 7, 5, 7 , 7]
res = []
for i in num:
if i not in res:
res.append(i)
print(res)
CodePudding user response:
Why not use np.unique?
import numpy as np
unique_num = np.unique(num)
https://numpy.org/doc/stable/reference/generated/numpy.unique.html