My target on daily basis is 250. For any given date, if the cum-daily_result has reached 250 then subsequent rows should have only 250 as expected results
In below table column 'ID' to 'cum_daily_result' are the input in data frame. The expected output is computed manually in column 'expected_daily_result'
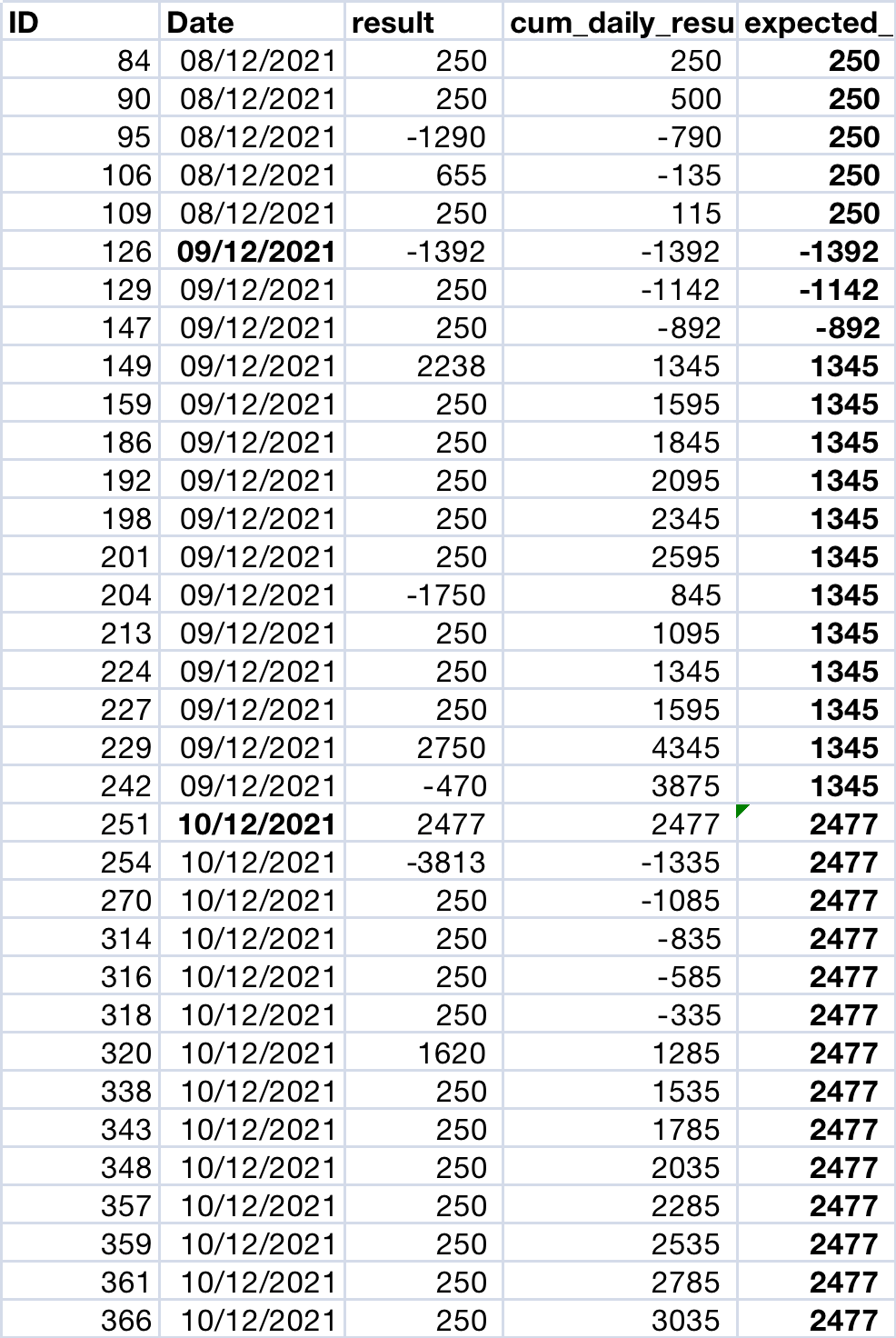
I tried the below code, but not giving the expected result,
if df['cum_daily_result'][-1] >= 250:
expected_daily_result = df['cum_daily_result'][-1]
else:
expected_daily_result = df['cum_daily_result']
CodePudding user response:
Consider using .clip(...)
expected_daily_result = df.cum_daily_result.clip(upper=250)
CodePudding user response:
make simple example text not image
example:
data = [['a', 250, 250], ['a', 250, 500], ['a', -1290, -790],
['b', -1392, -1392], ['b', 250, -1142], ['b', 250, -892], ['b', 2238, 1346],
['b', 250, 1596], ['c', 2477, 2477], ['c', -3813, -1336], ['c', 250, -1086]]
df = pd.DataFrame(data, columns=['col1', 'col2', 'col3'])
output(df):
col1 col2 col3
0 a 250 250
1 a 250 500
2 a -1290 -790
3 b -1392 -1392
4 b 250 -1142
5 b 250 -892
6 b 2238 1346
7 b 250 1596
8 c 2477 2477
9 c -3813 -1336
10 c 250 -1086
use groupby
idx = df[df['col3'] >= 250].groupby('col1').head(1).index
df.loc[idx, 'col4'] = 1
df['col4'] = df.groupby('col1')['col4'].bfill() * df['col3']
df['col4'] = df.groupby('col1')['col4'].ffill().astype('int')
output(df)
col1 col2 col3 col4
0 a 250 250 250
1 a 250 500 250
2 a -1290 -790 250
3 b -1392 -1392 -1392
4 b 250 -1142 -1142
5 b 250 -892 -892
6 b 2238 1346 1346
7 b 250 1596 1346
8 c 2477 2477 2477
9 c -3813 -1336 2477
10 c 250 -1086 2477