Fairly new to python, I have been struggling with creating a calculated column based off of the variable values of each item.
I Have this table below with DF being the dataframe name
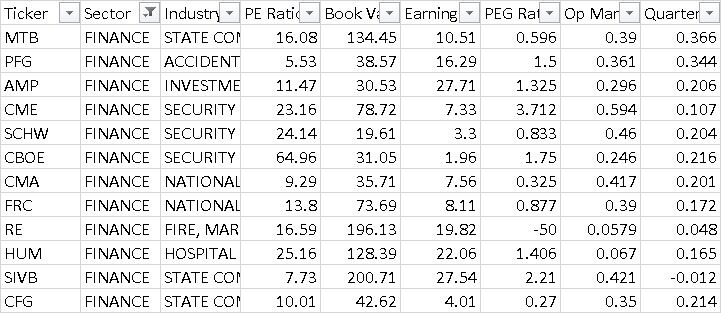
I am trying to create a 'PE Comp' Column that gets the PE value for each ticker, and divides it by the **Industry ** average PE Ratio.
My most successful attempt required me creating a .groupby industry dataframe (y) which has calculated the mean per industry. These numbers are correct. Once I did that I created this code block:
for i in DF['Industry']:
DF['PE Comp'] = DF['PE Ratio'] / y.loc[i,'PE Ratio']
However the numbers are coming out incorrect. I've tested this and the y.loc divisor is working fine with the right numbers, meaning that the issue is coming from the dividend.
Any suggestions on how I can overcome this?
Thanks in advance!
CodePudding user response:
You can use the Pandas Groupby transform:
The following takes the PE Ratio column and divides it by the mean of the grouped industries (expressed two different ways):
import pandas as pd
df = pd.DataFrame({"PE Ratio": [1,2,3,4,5,6,7],
"Industry": list("AABCBBC")})
# option 1
df["PE Comp"] = df["PE Ratio"] / df.groupby("Industry")["PE Ratio"].transform("mean")
# option 2
import numpy as np
df["PE Comp"] = df.groupby("Industry")["PE Ratio"].transform(lambda x: x/np.mean(x))
df
#Out[]:
# PE Ratio Industry PE Comp
#0 1 A 0.666667
#1 2 A 1.333333
#2 3 B 0.642857
#3 4 C 0.727273
#4 5 B 1.071429
#5 6 B 1.285714
#6 7 C 1.272727
CodePudding user response:
First, you MUST NOT ITERATE through a dataframe. It is not optimized at all and it is a misused of Pandas' DataFrame. Creating a new dataframe containing the averages is a good approach in my opinion. I think the line you want to write after is :
df['PE comp'] = df['PE ratio'] / y.loc[df['Industry']].value
I just have a doubt about y.loc[df['Industry']].value maybe you don't need .value or maybe you need to cast the value, I didn't test. But the spirit is that you new y DataFrame is like a dict containing the average of each Industry.