Consider the following RNN architecture :
regressor = Sequential()
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
regressor.add(Dense(units = 1))
Note the timestep used is 60 and this architecture is developed for time series prediction ( more specifically, stock price prediction). Here is the model summary :
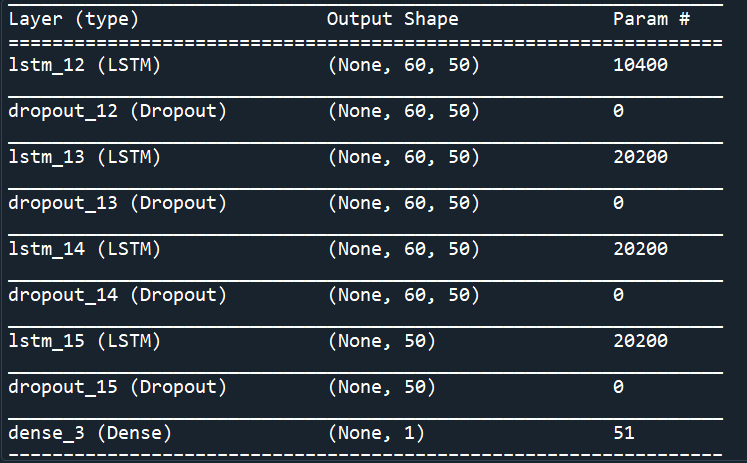
I just need to check my understanding about this architecture. The first layer is an LSTM layer with 50 cells, therefore, the output is a 3d matrix of shape (none,60,50), meaning that it will return the states of the 50 cells at every time step, hence, for every cell it will output 60 states for each step, so we will have the shape (none,60,50). none here is a placeholder for the batch size that will be determined when calling the fit or predict function. These values will be fully connected to the next LSTM layer. The same can be said for second and third LSTM layer. For the fourth LSTM layer, because of the return_sequence= False, Keras will return only the final hidden state at the final time step for each cell, and since we have 50 cells, then we will have 50 values for the hidden state, and hence, the output shape (none,50). These values are then connected to an output dense layer with one neuron that will compute the final value ,and hence, it has the shape (none,1). Is that correct please?
CodePudding user response:
Yeah you are right. LSTM works on the principle of recurrences, first you have to compute the the first sequence of an entity then only you can go further... Adding dropout between layers in LSTM is not a good strategty why you don't use dropout inside the LSTM layer. Onemore, thing use kernel_regularizer in the last layer that would add a penalty for large weights or inputs which are more in size.