I am working on a project which have to do image predictions using artifical intelligence,
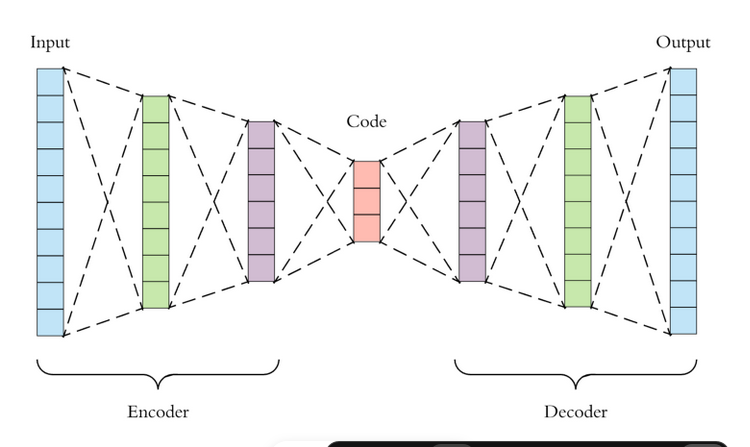
this is the image, you can see that the nodes are attached with each other, and first encoding the image and then hidden layer and then decoding layer.
My question is, the real implementation of autoencoder is very difficult to understand, is it possible to do coding of autoencoder nodes like we normaly do in data structures for creating linklist node BST node etc?
I want the code looks easy to understand.
like....
#include <iostream>
using namespace std;
struct node
{
double data[100][100];
struct node *next;
};
class autoencoder
{
struct node *head;
struct node *temp; // to traverse through the whole list
public:
LinkedList()
{
head = NULL;
}
void insert()
{
node *NewNode = new node;
cout << "Enter data :: ";
cin >> NewNode->data[100][100];
NewNode->next = 0;
if (head == 0)
{
head = temp = NewNode;
}
else
{
temp->next = NewNode;
temp = NewNode; // temp is treversing to newnode
}
}
void activation() // some activation function
void sigmoid fucntion // some sigmoid function
}
int main()
{
autoencoder obj;
obj.insertnode()
obj.activation()
obj.sigmoid()
}
this is sudo code type. My wquestion is the real autoencoder implementation include so much libraries and other stuff which is not understandable, is it possible to implement the nodes of autoEncoder like shown in the image?
I have a lot of search but didn't find any solution. If it is possible please let me know the guidence. If not please let me noe so that I will waste my time on searching this.
CodePudding user response:
Yes, it's definitely possible to implement neural networks using common data structures. For modern Neural Networks, the data structure of choice at top level is not the linked list but the Graph - linked lists are the simplest Graph type (just linear). More complex networks (e.g. ResNet) have more than one path.
One of the key things that you should do is to keep the weights and inputs separate. double data[100][100] is unclear to me. Are those the weights, or the image data you're processing? And besides, it's an autoencoder. Those dimensions should vary across the layers, as your picture shows. (And in the real world, we choose nice round numbers like 64 or 128)
Note that autoencoders aren't that special from a data structure perspective. They're just a set of layers. The key to autoencoders is how they're trained, and that's not visible in the structure,
CodePudding user response:
At its core, a node is fairly simple:
struct Node {
double value;
double bias = 0;
std::vector<std::pair<Node*, float>> connections;
double compute() {
value = bias;
for (auto&& [node, weight] : connections) {
value = node->value * weight;
}
return value;
}
};
A layer is a bunch of nodes:
using Layer = std::vector<Node>;
And a network is a bunch of layers. We assume everything is fully-connected:
struct Network {
std::vector<Layer> layers;
void addFCLayer(int size) {
Layer newLayer(size);
if (!layers.empty()) {
Layer& prevLayer = layers.back();
for (auto& newNode: newLayer) {
for (auto& prevNode: prevLayer) {
newNode.connections.emplace_back(&prevNode, rand());
}
}
}
layers.push_back(std::move(newLayer));
}
And finally, forward propagation is just calling compute layer per layer, skipping the first (input) layer. You can read the output values from network.layers.back()
void forwardProp() {
for (auto it = layers.begin(); it != layers.end(); it ) {
for (auto& node: *it) {
node.compute();
}
}
}
};
There is lots of "exercise left to the reader", of course:
- using predefined weights and biases instead of using
rand() - using a different activation function
- some nice scaffolding so you can feed in an image instead of setting a few hundred nodes' values and reading them back out.
- actually training/testing the network and updating weights