Good morning guys, my problem is simple:
Given a dataframe like this:
import pandas as pd
df = pd.DataFrame({ 'a': [1, 2, 3, 4, 5, 6],
'b': [8, 18, 27, 20, 33, 49],
'c': [2, 24, 6, 16, 20, 52]})
print(df)
I would like to retrieve for each row the maximum value and compare it with all the others. If the difference is >10, create another column with a string 'yes' or 'not'
a b c
0 1 8 2
1 2 18 24
2 3 27 6
3 4 20 16
4 5 33 20
5 6 49 52
I expect this result:
a b c res
0 1 8 2 not
1 2 18 24 not
2 3 27 6 yes
3 4 20 16 not
4 5 33 20 yes
5 6 49 52 not
Thanks a lot in advance.
CodePudding user response:
I guess, the below code can help:
import pandas as pd
df = pd.DataFrame({ 'a': [1, 2, 3, 4, 5, 6],
'b': [8, 18, 27, 20, 33, 49],
'c': [2, 24, 6, 16, 20, 52]})
def find(x):
if x > 10:
return "yes"
else:
return "not"
df["diff"] = df.max(axis=1) - df.apply(lambda row: row.nlargest(2).values[-1],axis=1)
df["res"] = df["diff"].apply(find)
df.drop(columns="diff", axis=0, inplace=True)
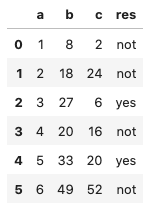
Output:
CodePudding user response:
import pandas as pd
df = pd.DataFrame({ 'a': [1, 2, 3, 4, 5, 6],
'b': [8, 18, 27, 20, 33, 49],
'c': [2, 24, 6, 16, 20, 52]})
def _max(row):
first, second = row.nlargest(2)
if first - second > 10:
return True
else:
return False
df["res"] = df.apply(_max, axis=1)
CodePudding user response:
This should do the trick.
Around twice to ten times as fast as other answers provided here
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6],
'b': [8, 18, 27, 20, 33, 49],
'c': [2, 24, 6, 16, 20, 52]})
df["res"] = df.apply(lambda row: "yes" if all(row.apply(lambda val: max(row) - val > 10 or val == max(row))) else "not", axis=1)
print(df)
results
a b c res
0 1 8 2 not
1 2 18 24 not
2 3 27 6 yes
3 4 20 16 not
4 5 33 20 yes
5 6 49 52 not