I'm attempting to overwrite the value named in a column called 'Group' when the value in a column called 'Keyword' is a duplicate with the adjacent value.
For example, because the string 'commercial office cleaning services' is duplicated, I'd like to overwrite the adjacent column to 'commercial cleaning services'.
Example Data
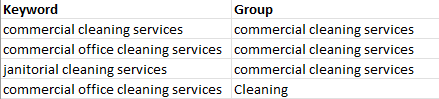
Desired Output
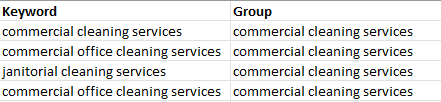
Minimum Reproducible Example
import pandas as pd
data = [
["commercial cleaning services", "commercial cleaning services"],
["commercial office cleaning services", "commercial cleaning services"],
["janitorial cleaning services", "commercial cleaning services"],
["commercial office services", "commercial cleaning"],
]
df = pd.DataFrame(data, columns=["Keyword", "Group"])
print(df)
I'm fairly new to pandas and not sure where to start, I've reached a dead end Googling and searching stackoverflow.
CodePudding user response:
IIUC, use duplicated with mask and ffill :
#is the keyword duplicated ?
m = df['Keyword'].duplicated()
df['Group'] = df['Group'].mask(m).ffill()
# Output:
print(df)
Keyword Group
0 commercial cleaning services commercial cleaning services
1 commercial office cleaning services commercial cleaning services
2 janitorial cleaning services commercial cleaning services
3 commercial office cleaning services commercial cleaning services
NB: The reproducible example does not match the image of the input (https://i.stack.imgur.com/fPWPa.png)
{kind=link}