I have the following textfile from an LFT command.
2 [14080] [100.0.0.0 - 100.255.255.255] 100.5.254.150 6.3ms
3 [14080] [100.0.0.0 - 100.255.255.255] 100.8.254.149 5.7ms
4 [15169] [GOOGLE] 142.250.164.139 17.5ms
5 [15169] [GOOGLE] 142.250.164.138 10.9ms
6 [15169] [GOOGLE] 72.14.233.63 12.8ms
7 [15169] [GOOGLE] 142.250.210.131 9.6ms
8 [15169] [GOOGLE] 142.250.78.78 11.9ms
Where each space could be understood like a field. I tried convert this textfile in a JSON file but I have that:
{
"emp1": {
"Jumps": "2",
"System": "[14080]",
"Adress": "[100.0.0.0",
"IP": "-",
"Delay": "100.255.255.255] 100.5.254.150 6.3ms"
},
"emp2": {
"Jumps": "3",
"System": "[14080]",
"Adress": "[100.0.0.0",
"IP": "-",
"Delay": "100.255.255.255] 100.5.254.150 5.7ms"
},
"emp3": {
"Jumps": "4",
"System": "[15169]",
"Adress": "[GOOGLE]",
"IP": "142.250.164.139",
"Delay": "17.5ms"
},
"emp4": {
"Jumps": "5",
"System": "[15169]",
"Adress": "[GOOGLE]",
"IP": "142.250.164.138",
"Delay": "10.9ms"
},
"emp5": {
"Jumps": "6",
"System": "[15169]",
"Adress": "[GOOGLE]",
"IP": "72.14.233.63",
"Delay": "12.8ms"
},
"emp6": {
"Jumps": "7",
"System": "[15169]",
"Adress": "[GOOGLE]",
"IP": "142.250.210.131",
"Delay": "9.6ms"
},
"emp7": {
"Jumps": "8",
"System": "[15169]",
"Adress": "[GOOGLE]",
"IP": "142.250.78.78",
"Delay": "11.9ms"
}
}
As you can see, the first two fields in the "Delay" section are worng.
How I can fix it? What can I do for that?
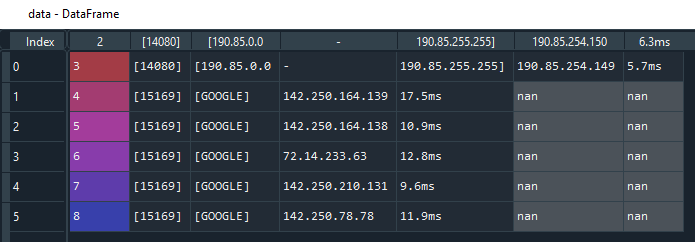
I tried to use pandas too but what I get is the same answer:
data = pd.read_csv("file.txt", sep=r'\s ')
CodePudding user response:
You can try to parse the text with re module:
text = """\
2 [14080] [100.0.0.0 - 100.255.255.255] 100.5.254.150 6.3ms
3 [14080] [100.0.0.0 - 100.255.255.255] 100.8.254.149 5.7ms
4 [15169] [GOOGLE] 142.250.164.139 17.5ms
5 [15169] [GOOGLE] 142.250.164.138 10.9ms
6 [15169] [GOOGLE] 72.14.233.63 12.8ms
7 [15169] [GOOGLE] 142.250.210.131 9.6ms
8 [15169] [GOOGLE] 142.250.78.78 11.9ms"""
import re
pat = re.compile(r"(?m)^\s*(\d )\s*\[(.*?)\]\s*\[(.*?)\]\s*(\S )\s*(\S )")
out = {}
for i, t in enumerate(pat.findall(text), 1):
out[f"emp{i}"] = {
"Jumps": t[0],
"System": t[1],
"Adress": t[2],
"IP": t[3],
"Delay": t[4],
}
print(out)
Prints:
{
"emp1": {
"Jumps": "2",
"System": "14080",
"Adress": "100.0.0.0 - 100.255.255.255",
"IP": "100.5.254.150",
"Delay": "6.3ms",
},
"emp2": {
"Jumps": "3",
"System": "14080",
"Adress": "100.0.0.0 - 100.255.255.255",
"IP": "100.8.254.149",
"Delay": "5.7ms",
},
"emp3": {
"Jumps": "4",
"System": "15169",
"Adress": "GOOGLE",
"IP": "142.250.164.139",
"Delay": "17.5ms",
},
"emp4": {
"Jumps": "5",
"System": "15169",
"Adress": "GOOGLE",
"IP": "142.250.164.138",
"Delay": "10.9ms",
},
"emp5": {
"Jumps": "6",
"System": "15169",
"Adress": "GOOGLE",
"IP": "72.14.233.63",
"Delay": "12.8ms",
},
"emp6": {
"Jumps": "7",
"System": "15169",
"Adress": "GOOGLE",
"IP": "142.250.210.131",
"Delay": "9.6ms",
},
"emp7": {
"Jumps": "8",
"System": "15169",
"Adress": "GOOGLE",
"IP": "142.250.78.78",
"Delay": "11.9ms",
},
}
CodePudding user response:
Andrej's answer is already perfect, just wanted to add another solution:
with open("textfile.txt", 'r') as f:
s = f.readlines()
data = {}
for i, value in enumerate(s, 1):
t = value.split('\n')[0].split()
data[f"emp{i}"] = {
"Jumps": t[0],
"System": t[1],
"Adress": t[2] if len(t)==5 else ''.join(t[2:5]),
"IP": t[-2],
"Delay": t[-1]}
This prints:
{
'emp1':{
'Jumps': '2',
'System': '[14080]',
'Adress': '[100.0.0.0-100.255.255.255]',
'IP': '100.5.254.150', 'Delay': '6.3ms'},
'emp2': {
'Jumps': '3',
'System': '[14080]',
'Adress': '[100.0.0.0-100.255.255.255]',
'IP': '100.8.254.149',
'Delay': '5.7ms'},
'emp3': {
'Jumps': '4',
'System': '[15169]',
'Adress': '[GOOGLE]',
'IP': '142.250.164.139',
'Delay': '17.5ms'},
'emp4': {
'Jumps': '5',
'System': '[15169]',
'Adress': '[GOOGLE]',
'IP': '142.250.164.138',
'Delay': '10.9ms'},
'emp5': {
'Jumps': '6',
'System': '[15169]',
'Adress': '[GOOGLE]',
'IP': '72.14.233.63',
'Delay': '12.8ms'},
'emp6': {
'Jumps': '7',
'System': '[15169]',
'Adress': '[GOOGLE]',
'IP': '142.250.210.131',
'Delay': '9.6ms'},
'emp7': {
'Jumps': '8',
'System': '[15169]',
'Adress': '[GOOGLE]',
'IP': '142.250.78.78',
'Delay': '11.9ms'}
}