I am looking to implement concurrency inside part of my app in order to speed up processing. The input array can be a large array, that I need to check multiple things related to it. This would be some sample code.
EDITED:
So this is helpful for looking at striding through the array, which was something else I was looking at doing, but I think the helpful answers are sliding away from the original question, due to the fact that I already have a DispatchQueue.concurrentPerform present in the code.
Within a for loop multiple times, I was looking to implement other for loops, due to having to relook at the same data multiple times. The inputArray is an array of structs, so in the outer loop, I am looking at one value in the struct, and then in the inner loops I am looking at a different value in the struct. In the change below I made the two inner for loops function calls to make the code a bit more clear. But in general, I would be looking to make the two funcA and funcB calls, and wait until they are both done before continuing in the main loop.
//assume the startValues and stop values will be within the bounds of the
//array and wont under/overflow
private func funcA(inputArray: [Int], startValue: Int, endValue: Int) -> Bool{
for index in startValue...endValue {
let dataValue = inputArray[index]
if dataValue == 1_000_000 {
return true
}
}
return false
}
private func funcB(inputArray: [Int], startValue: Int, endValue: Int) -> Bool{
for index in startValue...endValue {
let dataValue = inputArray[index]
if dataValue == 10 {
return true
}
}
return false
}
private func testFunc(inputArray: [Int]) {
let dataIterationArray = Array(Set(inputArray))
let syncQueue = DispatchQueue(label: "syncQueue")
DispatchQueue.concurrentPerform(iterations: dataIterationArray.count) { index in
//I want to do these two function calls starting roughly one after another,
//to work them in parallel, but i want to wait until both are complete before
//moving on. funcA is going to take much longer than funcB in this case,
//just because there are more values to check.
let funcAResult = funcA(inputArray: dataIterationArray, startValue: 10, endValue: 2_000_000)
let funcBResult = funcB(inputArray: dataIterationArray, startValue: 5, endValue: 9)
//Wait for both above to finish before continuing
if funcAResult && funcBResult {
print("Yup we are good!")
} else {
print("Nope")
}
//And then wait here until all of the loops are done before processing
}
}
CodePudding user response:
In your revised question, you contemplated a concurrentPerform loop where each iteration called funcA and then funcB and suggested that you wanted them “to work them in parallel”.
Unfortunately. that is not how 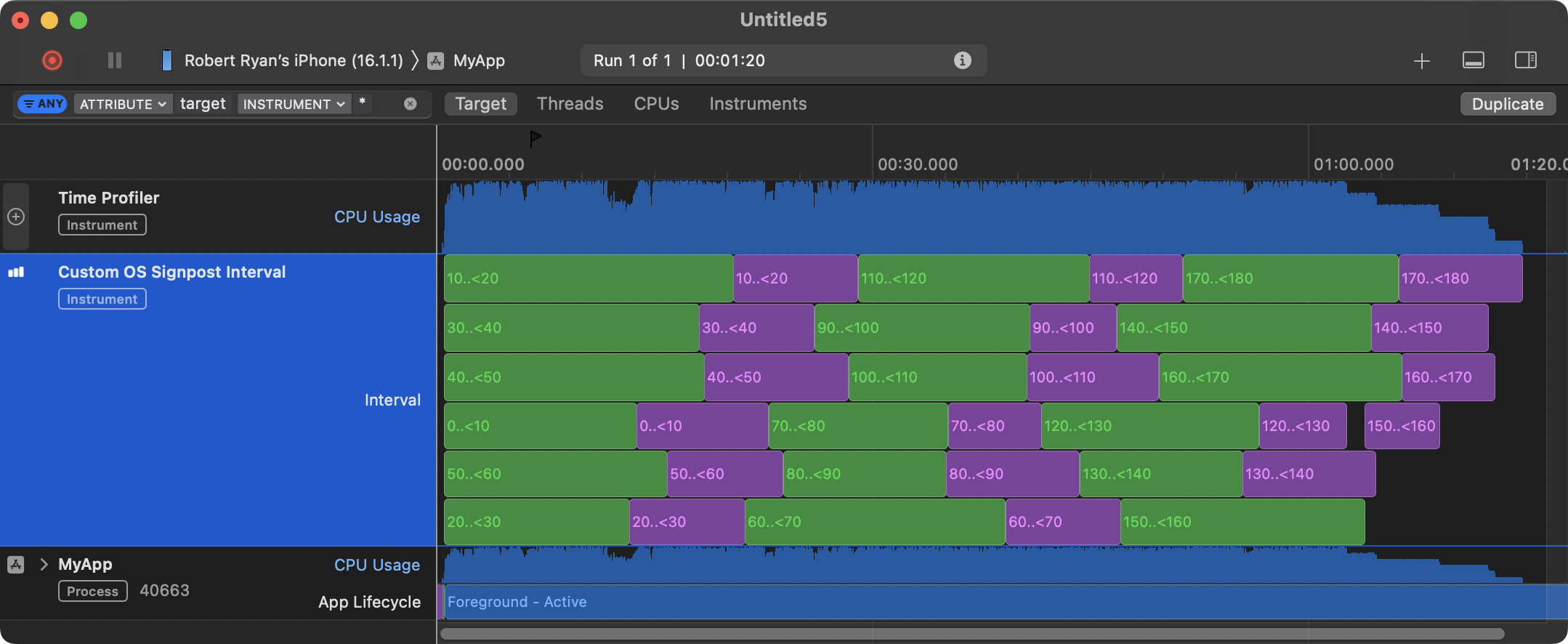
But, as you can see, although funcB for a given range of indices will not start until funcA finishes for the same range of indices, it does not really matter, because we are still enjoying full parallelism on the device, taking advantage of all the CPU cores.
I contend that, given that we are enjoying parallelism, that there is little benefit to contemplate making funcA and funcB run concurrently with respect to each other, too. Just let the individual iterations run parallel to each other, but let A and B run sequentially, and call it a day.
If you really want to have funcA and funcB run parallel with each other, as well, you will need to consider a different pattern. The concurrentPerform simply is not designed for launching parallel tasks that, themselves, are asynchronous. You could consider:
Have
concurrentPerformlaunch, using my example, 36 iterations, half of which dofuncAand half of which dofuncB.Or you might consider using
OperationQueuewith a reasonablemaxConcurrentOperationCount(but you do not enjoy the dynamic limitation of the degree concurrency to the device’s CPU cores).Or you might use an
async-awaittask group, which will limit itself to the cooperative thread pool.
But you will not want to have concurrentPerform have a closure that launches asynchronous tasks or introduces additional parallel execution.
And, as I discuss below, the example provided in the question is not a good candidate for parallel execution. Mere tests of equality are not computationally intensive enough to enjoy parallelism benefits. It will undoubtedly just be slower than the serial pattern.
My original answer, below, outlines the basic concurrentPerform considerations.
The basic idea is to “stride” through the values. So calculate how many “iterations” are needed and calculate the “start” and “end” index for each iteration:
private func testFunc(inputArray: [Int]) {
DispatchQueue.global().async {
let array = Array(Set(inputArray))
let syncQueue = DispatchQueue(label: "syncQueue")
// calculate how many iterations will be needed
let count = array.count
let stride = 10
let (quotient, remainder) = count.quotientAndRemainder(dividingBy: stride)
let iterations = remainder == 0 ? quotient : quotient 1
// now iterate
DispatchQueue.concurrentPerform(iterations: iterations) { iteration in
// calculate the `start` and `end` indices
let start = stride * iteration
let end = min(start stride, count)
// now loop through that range
for index in start ..< end {
let value = array[index]
print("iteration =", iteration, "index =", index, "value =", value)
}
}
// you won't get here until they're all done; obviously, if you
// want to now update your UI or model, you may want to dispatch
// back to the main queue, e.g.,
//
// DispatchQueue.main.async {
// ...
// }
}
}
Note, if something is so slow that it merits concurrentPerform, you probably want to dispatch the whole thing to a background queue, too. Hence the DispatchQueue.global().async {…} shown above. You would probably want to add a completion handler to this method, now that it runs asynchronously, but I will leave that to the reader.
Needless to say, there are quite a few additional considerations:
- The stride should be large enough to ensure there is enough work on each iteration to offset the modest overhead introduced by multithreading. Some experimentation is often required to empirically determine the best striding value.
- The work done in each thread must be significant (again, to justify the multithreading overhead). I.e., simply printing values is obviously not enough. (Worse,
printstatements compound the problem by introducing a hidden synchronization.) Even building a new array with some simple calculation will not be sufficient. This pattern really only works if you are doing something very computationally intensive. - You have a “sync” queue, which suggests that you understand that you need to synchronize the combination of the results of the various iterations. That is good. I will point out, though, that you will want to minimize the total number of synchronizations you do. E.g. let’s say you have 1000 values and you end up doing 10 iterations, each striding through 100 values. You generally want to have each iteration build a local result and do a single synchronization for each iteration. Using my example, you should strive to end up with only 10 total synchronizations, not 1000 of them, otherwise excessive synchronization can easily negate any performance gains.
Bottom line, making a routine execute in parallel is complicated and you can easily find that the process is actually slower than the serial rendition. Some processes simply don’t lend themselves to parallel execution. We obviously cannot comment further without understanding what your processes entail. Sometimes other technologies, such as Accelerate or Metal can achieve better results.
CodePudding user response:
I will explain it here, since comment is too small, but will delete later if it doesn't answer the question.
Instead of looping over iterations: dataIterationArray.count, have number of iterations based on number of desired parallel streams of work, not based on array size. For example as you mentioned you want to have 3 streams of work, then you should have 3 iterations, each iteration processing independent part of work:
DispatchQueue.concurrentPerform(iterations: 3) { iteration in
switch iteration {
case 0:
for i in 1...10{
print ("i \(i)")
}
case 1:
for j in 11...20{
print ("j \(j)")
}
case 2:
for k in 21...30{
print ("k \(k)")
}
}
}
And the "And then wait here until all of the loops are done before processing" will happen automatically, this is what concurrentPerform guarantees.