I have a JSON file. While the original file is quite large, I reduced to a much smaller reproducible example for the purposes of this question (I still get the same error no matter what size):
{
"relationships_followers": [
{
"title": "",
"media_list_data": [
],
"string_list_data": [
{
"href": "https://www.instagram.com/testaccount1",
"value": "testaccount1",
"timestamp": 1669418204
}
]
},
{
"title": "",
"media_list_data": [
],
"string_list_data": [
{
"href": "https://www.instagram.com/testaccount2",
"value": "testaccount2",
"timestamp": 1660426426
}
]
},
{
"title": "",
"media_list_data": [
],
"string_list_data": [
{
"href": "https://www.instagram.com/testaccount3",
"value": "testaccount3",
"timestamp": 1648230499
}
]
},
{
"title": "",
"media_list_data": [
],
"string_list_data": [
{
"href": "https://www.instagram.com/testaccount4",
"value": "testaccount4",
"timestamp": 1379513403
}
]
}
]
}
I am attempting to convert it into a dataframe in R, which contains the values for href, value, and the timestamp variables:
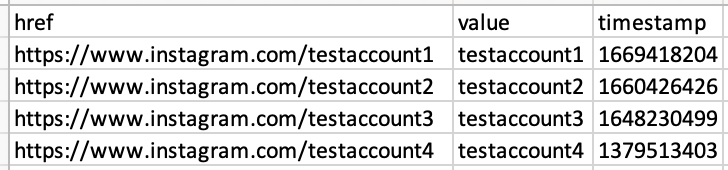
But when I run the following, which I pulled from another SO answer about converting JSON to R:
library("rjson")
result <- fromJSON(file = "test_file.json")
json_data_frame <- as.data.frame(result)
I get met with this error about differing rows.
Error in (function (..., row.names = NULL, check.rows = FALSE, check.names = TRUE, :
arguments imply differing number of rows: 1, 0
How can I get what I have into the desired DF format?
CodePudding user response:
Looks like the data is nested...
Try this:
library("rjson")
library("dplyr")
result <- fromJSON(file = "test_file.json")
result_list <-sapply(result$relationships_followers,
"[[", "string_list_data")
json_data_frame <- bind_rows(result_list)
CodePudding user response:
That is because there is nested data.
df<- as.data.frame(do.call(rbind, lapply(
lapply(result$relationships_followers, "[[", "string_list_data"), "[[", 1)))
df
#> href value timestamp
#> "https://www.instagram.com/testaccount1" "testaccount1" 1669418204
#> "https://www.instagram.com/testaccount2" "testaccount2" 1660426426
#> "https://www.instagram.com/testaccount3" "testaccount3" 1648230499
#> "https://www.instagram.com/testaccount4" "testaccount4" 1379513403
NOTE: jsonlite package does a better job on parsing data.frame by default.