I have written a code that generates x and y data and am able to plot it.
# Number of observations
n <- 250
# x randomly drawn from a continuous uniform distribution with bounds [0,10]
x <- runif(min = 0, max = 1, n = sample(n))
# Error term from Normal distribution
error <- rnorm(n = n, mean = 0, sd = 2)
beta_0 <- 1
beta_1 <- -1
y <- beta_0*x (beta_1*x - error)
library(tibble)
df <- tibble(x = x, y = y)
df
library(ggplot2)
ggplot(data = df, aes(x = x, y = y)) geom_point()
labs(title = "y = f(x)")
I get an graph image like this:
I also get a data table like this of different coordinate data:
| x | y. |
|---|---|
| 0.139 | -2.87 |
| 0.981 | 1.48 |
I would like to now randomly classify my data, such that my table looks like:
| x | y. | Group1 | Group2 |
|---|---|---|---|
| 0.139 | -2.87 | -1 | 1 |
| 0.981 | 1.48 | 1 | -1 |
Where 1 represents that points membership to the group and -1 representing the point not being affiliated to the group. On the graph this would look like I had blue dots for Group1 membership vs red dots for Group2 membership.
Any help with this would be greatly appreciated.
Thank you.
CodePudding user response:
To do it the way you suggested (with one column for group 1 and one column for group 2), you could do:
library(dplyr)
library(ggplot2)
df %>%
mutate(group1 = sample(c(-1, 1), n, TRUE),
group2 = -group1) %>%
ggplot(aes(x = x, y = y, color = factor(group1)))
geom_point()
scale_color_brewer('group', palette = 'Set1',
labels = c('Group 1', 'Group 2'))
labs(title = "y = f(x)")
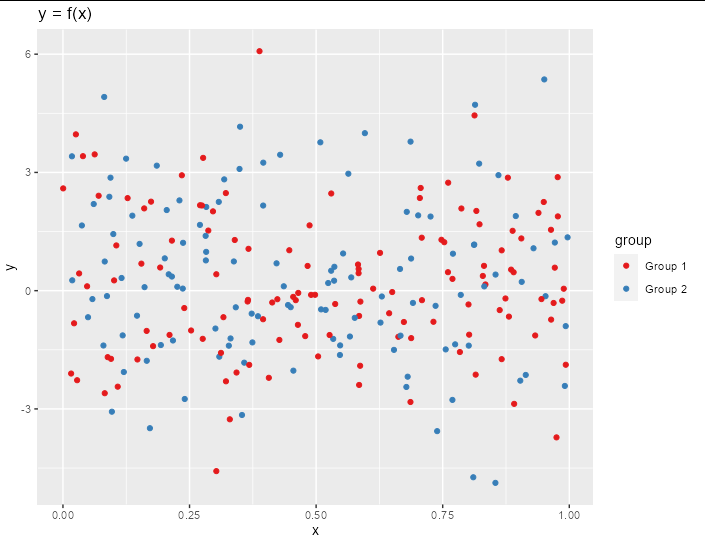
However, it seems a bit redundant to me having two mutually exclusive binary columns. You could just have a single column called group which is either group 1 or group 2:
df %>%
mutate(group = sample(c('Group 1', 'Group 2'), n, TRUE)) %>%
ggplot(aes(x = x, y = y, color = group))
geom_point()
scale_color_brewer(palette = 'Set1')
labs(title = "y = f(x)"