I have some data, that needs to be clusterised into groups. That should be done by a few predifined conditions.
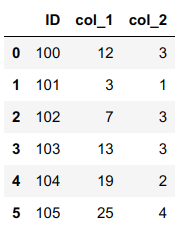
Suppose we have the following table:
d = {'ID': [100, 101, 102, 103, 104, 105],
'col_1': [12, 3, 7, 13, 19, 25],
'col_2': [3, 1, 3, 3, 2, 4]
}
df = pd.DataFrame(data=d)
df.head()
Here, I want to group ID based on the following ranges, conditions, on col_1 and col_2.
For col_1 I divide values into following groups: [0, 10], [11, 15], [16, 20], [20, inf]
For col_2 just use the df['col_2'].unique() values: [1], [2], [3], [4].
The desired groupping is in group_num column:
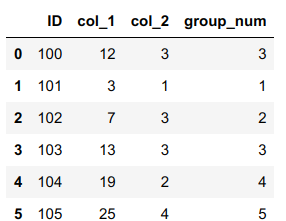
notice, that 0 and 3 rows have the same group number and the order, in which group number is assigned.
For now, I only came up with if-elif function to pre-define all the groups. It's not the solution for now cause in my real task there are far more ranges and confitions.
My code snippet, if it's relevant:
# This logic is not working cause here I have to predefine all the groups configurations, aka numbers,
# but I want to make groups "dymanicly":
# first group created and if the next row is not in that group -> create new one
def groupping(val_1, val_2):
# not using match case here, cause my Python < 3.10
if ((val_1 >= 0) and (val_1 <10)) and (val_2 == 1):
return 1
elif ((val_1 >= 0) and (val_1 <10)) and (val_2 == 2):
return 2
elif ...
...
df['group_num'] = df.apply(lambda x: groupping(x.col_1, x.col_2), axis=1)
CodePudding user response:
make dataframe for chking group
bins = [0, 10, 15, 20, float('inf')]
df1 = df[['col_1', 'col_2']].assign(col_1=pd.cut(df['col_1'], bins=bins, right=False)).sort_values(['col_1', 'col_2'])
df1
col_1 col_2
1 [0.0, 10.0) 1
2 [0.0, 10.0) 3
0 [10.0, 15.0) 3
3 [10.0, 15.0) 3
4 [15.0, 20.0) 2
5 [20.0, inf) 4
chk group by df1
df1.ne(df1.shift(1)).any(axis=1).cumsum()
output:
1 1
2 2
0 3
3 3
4 4
5 5
dtype: int32
make output to group_num column
df.assign(group_num=df1.ne(df1.shift(1)).any(axis=1).cumsum())
result:
ID col_1 col_2 group_num
0 100 12 3 3
1 101 3 1 1
2 102 7 3 2
3 103 13 3 3
4 104 19 2 4
5 105 25 4 5
CodePudding user response:
Not sure I understand the full logic, can't you use pandas.cut:
bins = [0, 10, 15, 20, np.inf]
df['group_num'] = pd.cut(df['col_1'], bins=bins,
labels=range(1, len(bins)))
Output:
ID col_1 col_2 group_num
0 100 12 3 2
1 101 3 1 1
2 102 7 3 1
3 103 13 2 2
4 104 19 3 3
5 105 25 4 4