game_num = range(1,102,1)
player_name = ['Fred']*101
dict = {'name':player_name,'game_num':game_num}
df = pd.DataFrame(dict)
df['percentile_bin'] = pd.qcut(df['game_num'],100,list(range(1,101)))
If I enter df.percentile_bin.nunique() I get 98 which indicates that 2 percentile bins are not populated.
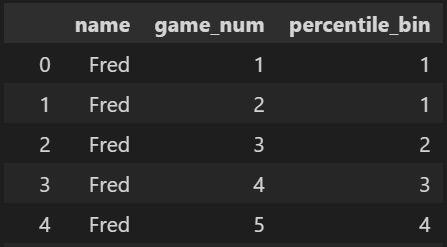
You can see for instance below, that game_num 2 is allocated to the 1st percentile_bin along with game_num 1. Why is this?
I would have expected pd.qcut(100,list(range(1,101))) to allocate 100 percentile bins to this dataframe, each populated by 1 row, with exactly 1 extra (because there was 101 rows).
CodePudding user response:
It's because of the rounding error of IEEE 754 floating-point numbers.
This can be seen in the returned bins of the pandas.qcut().
cats, bins = pd.qcut(range(1,102,1), 100, retbins=True)
for e in bins:
print(e)
This will output the following.
...
28.0
29.000000000000004
29.999999999999996
31.0
...
54.0
56.00000000000001
57.00000000000001
58.00000000000001
58.99999999999999
60.0
...
So, the categories(intervals) (29.000000000000004,29.999999999999996] and (58.00000000000001, 58.99999999999999] will not be in the returned categorical data.
If you want just 100 intervals, you can use pandas.cut() like this.
cats = pd.cut(range(1, 102), 100)