How can this SELECT query be tuned any further or this is the ONLY efficient way? I'm using Oracle Exadata 19c.
It joins two tables multiple times but on different conditions and returns data as different columns.
There is a better way but I don't know what it is.
DDLs/ DMLs to try it out:
CREATE TABLE TRAN (
C1 VARCHAR2(50) NOT NULL,
C2 VARCHAR2(50),
C3 VARCHAR2(50),
C4 VARCHAR2(50),
C5 VARCHAR2(50),
C6 VARCHAR2(50),
C7 VARCHAR2(50),
C8 VARCHAR2(50),
C9 VARCHAR2(50)
);
CREATE TABLE ADDR (
C1 VARCHAR2(50) NOT NULL,
C2 VARCHAR2(50),
BRANCH VARCHAR2(50),
ADDR VARCHAR2(50)
);
insert into TRAN (C1, C2, C3, C4, C5, C6, C7, C8, C9) values ('A111', 'Q1', 'Q1', 'Q1', 'Q1', 'Q1', 'Q1', 'Q1', 'Q1');
insert into TRAN (C1, C2, C3, C4, C5, C6, C7, C8, C9) values ('A222', 'Q2', 'Q2', 'Q2', null, null, null, null, 'Q2');
insert into TRAN (C1, C2, C3, C4, C5, C6, C7, C8, C9) values ('A333', 'Q3', 'Q3', 'Q3', 'Q3', 'Q3', 'Q3', 'Q3', 'Q3');
insert into TRAN (C1, C2, C3, C4, C5, C6, C7, C8, C9) values ('A444', null, null, null, null, 'Q4', 'Q4', 'Q4', 'Q4');
insert into ADDR (C1, C2, BRANCH, ADDR) values ('A111', 'Q1', 'CHN', 'INDIA');
insert into ADDR (C1, C2, BRANCH, ADDR) values ('A222', 'Q2','BLR', 'USA');
insert into ADDR (C1, C2, BRANCH, ADDR) values ('A444', 'Q4', 'HYD', 'UK');
commit;
Select Query:
WITH T1 as (SELECT tran.* FROM tran),
T2 as (SELECT ADDR.* FROM ADDR)
SELECT
T1.C1,
T21.BRANCH AS BRANCH1,
T21.ADDR AS ADDR1,
T22.BRANCH AS BRANCH2,
T22.ADDR AS ADDR2,
T23.BRANCH AS BRANCH3,
T23.ADDR AS ADDR3,
T24.BRANCH AS BRANCH4,
T24.ADDR AS ADDR4,
T25.BRANCH AS BRANCH5,
T25.ADDR AS ADDR5,
T26.BRANCH AS BRANCH6,
T26.ADDR AS ADDR6,
T27.BRANCH AS BRANCH7,
T27.ADDR AS ADDR7,
T28.BRANCH AS BRANCH8,
T28.ADDR AS ADDR8
FROM T1
LEFT OUTER JOIN T2 T21 ON T1.C1 = T21.C1 AND T1.C2 = T21.C2
LEFT OUTER JOIN T2 T22 ON T1.C1 = T22.C1 AND T1.C3 = T22.C2
LEFT OUTER JOIN T2 T23 ON T1.C1 = T23.C1 AND T1.C4 = T23.C2
LEFT OUTER JOIN T2 T24 ON T1.C1 = T24.C1 AND T1.C5 = T24.C2
LEFT OUTER JOIN T2 T25 ON T1.C1 = T25.C1 AND T1.C6 = T25.C2
LEFT OUTER JOIN T2 T26 ON T1.C1 = T26.C1 AND T1.C7 = T26.C2
LEFT OUTER JOIN T2 T27 ON T1.C1 = T27.C1 AND T1.C8 = T27.C2
LEFT OUTER JOIN T2 T28 ON T1.C1 = T28.C1 AND T1.C9 = T28.C2;
For every join, the first condition is on the same columns but the second one differs, with different columns from T1 to the same column in T2.
I have rewritten those multiple joins using OR and multiple CASE statements in a SELECT clause but the execution time is higher despite the low cost.
For the given output, referring table T2 8 times is the only way?
Expected Input/Output: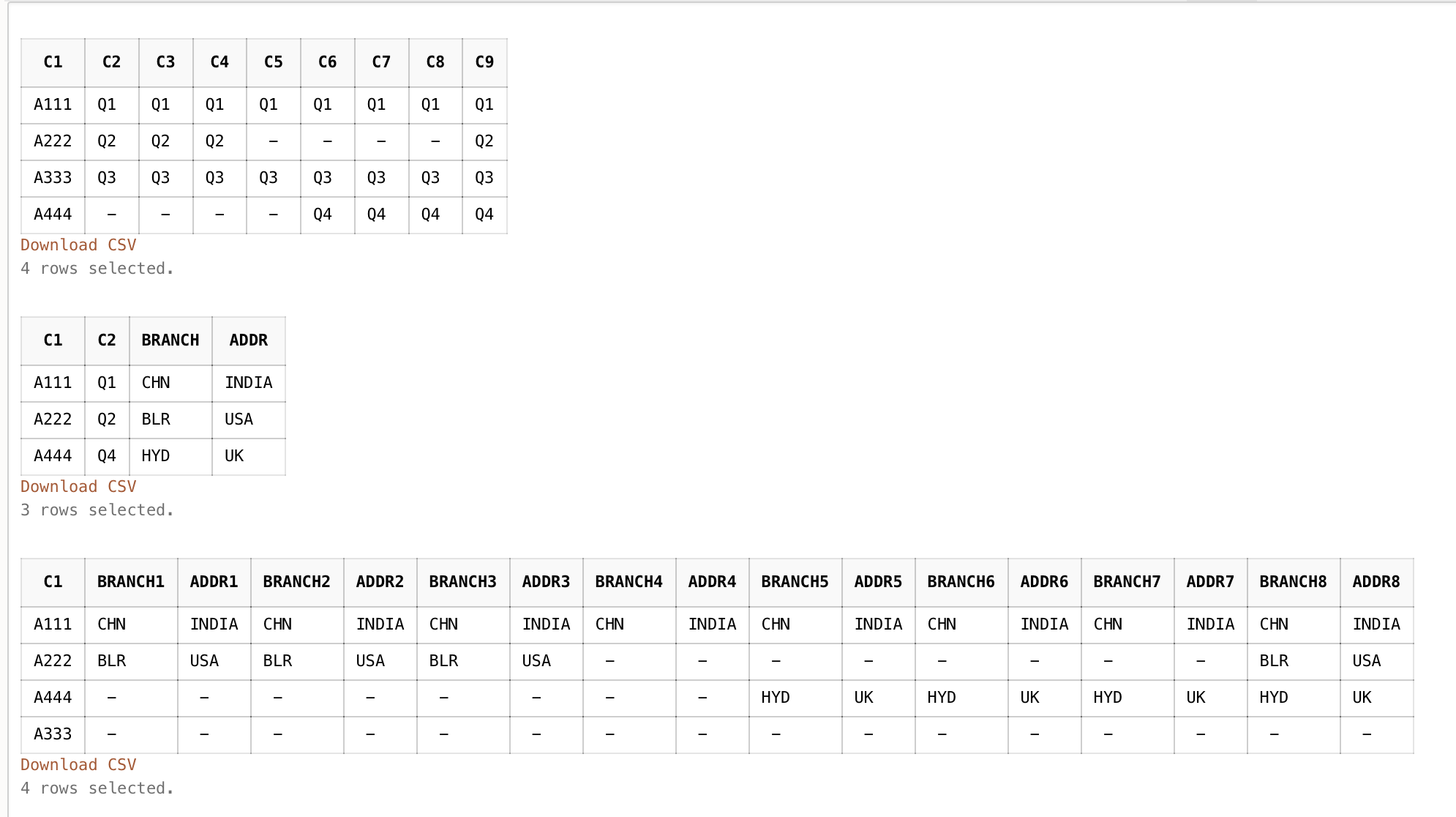
CodePudding user response:
If you are only expecting one row for each C1 value then you can JOIN once and pivot using conditional aggregation:
SELECT t.c1,
MAX(CASE WHEN a.c2 = t.c2 THEN a.branch END) AS branch1,
MAX(CASE WHEN a.c2 = t.c2 THEN a.addr END) AS addr1,
MAX(CASE WHEN a.c2 = t.c3 THEN a.branch END) AS branch2,
MAX(CASE WHEN a.c2 = t.c3 THEN a.addr END) AS addr2,
MAX(CASE WHEN a.c2 = t.c4 THEN a.branch END) AS branch3,
MAX(CASE WHEN a.c2 = t.c4 THEN a.addr END) AS addr3,
MAX(CASE WHEN a.c2 = t.c5 THEN a.branch END) AS branch4,
MAX(CASE WHEN a.c2 = t.c5 THEN a.addr END) AS addr4,
MAX(CASE WHEN a.c2 = t.c6 THEN a.branch END) AS branch5,
MAX(CASE WHEN a.c2 = t.c6 THEN a.addr END) AS addr5,
MAX(CASE WHEN a.c2 = t.c7 THEN a.branch END) AS branch6,
MAX(CASE WHEN a.c2 = t.c7 THEN a.addr END) AS addr6,
MAX(CASE WHEN a.c2 = t.c8 THEN a.branch END) AS branch7,
MAX(CASE WHEN a.c2 = t.c8 THEN a.addr END) AS addr7,
MAX(CASE WHEN a.c2 = t.c9 THEN a.branch END) AS branch8,
MAX(CASE WHEN a.c2 = t.c9 THEN a.addr END) AS addr8
FROM tran t
LEFT OUTER JOIN addr a
ON ( t.c1 = a.c1
AND a.c2 IN (t.c2, t.c3, t.c4, t.c5, t.c6, t.c7, t.c8, t.c9))
GROUP BY t.c1
Which, for the sample data, outputs:
| C1 | BRANCH1 | ADDR1 | BRANCH2 | ADDR2 | BRANCH3 | ADDR3 | BRANCH4 | ADDR4 | BRANCH5 | ADDR5 | BRANCH6 | ADDR6 | BRANCH7 | ADDR7 | BRANCH8 | ADDR8 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A444 | null | null | null | null | null | null | null | null | HYD | UK | HYD | UK | HYD | UK | HYD | UK |
| A333 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| A111 | CHN | INDIA | CHN | INDIA | CHN | INDIA | CHN | INDIA | CHN | INDIA | CHN | INDIA | CHN | INDIA | CHN | INDIA |
| A222 | BLR | USA | BLR | USA | BLR | USA | null | null | null | null | null | null | null | null | BLR | USA |