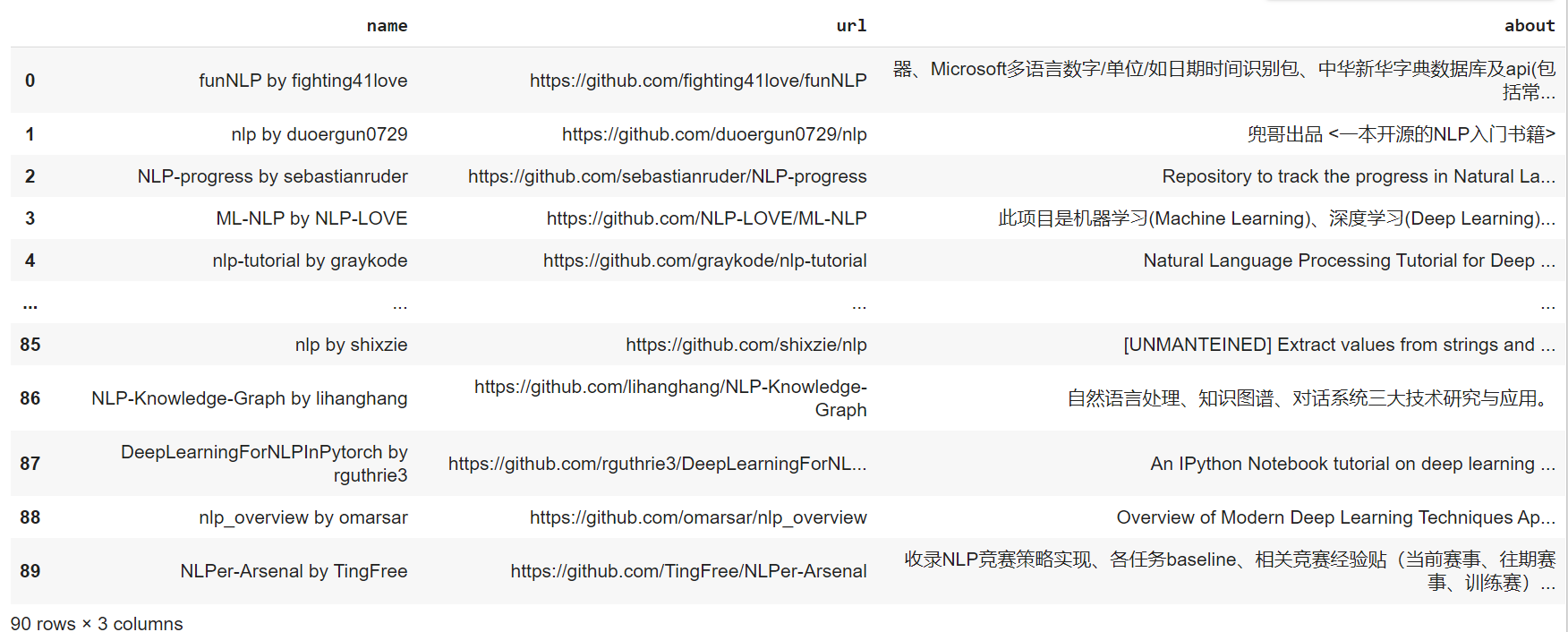
I'm trying to create a dataframe from a webscraping. Precisely: from a search of a topic on github, the objective is to retrieve the name of the owner of the repo, the link and the about.
I have many problems.
1. The search shows that there are, for example, more than 300,000 repos, but my scraping can only get the information from 90. I would like to scrape all available repos.
2. Sometimes about is empty. It stops me after creating a dataframe
ValueError: All arrays must be of the same length
3. My search for names is completely strange.
My code:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 5.1.1; SM-G928X Build/LMY47X) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.83 Mobile Safari/537.36'}
search_topics = "https://github.com/search?p="
stock_urls = []
stock_names = []
stock_about = []
for page in range(1, 99):
req = requests.get(search_topics str(page) "&q=" "nlp" "&type=Repositories", headers = headers)
soup = BeautifulSoup(req.text, "html.parser")
#about
for about in soup.select("p.mb-1"):
stock_about.append(about.text)
#urls
for url in soup.findAll("a", attrs = {"class":"v-align-middle"}):
link = url['href']
complete_link = "https://github.com" link
stock_urls.append(complete_link)
#profil name
for url in soup.findAll("a", attrs = {"class":"v-align-middle"}):
link = url['href']
names = re.sub(r"\/(.*)\/(.*)", "\1", link)
stock_names.append(names)
dico = {"name": stock_names, "url": stock_urls, "about": stock_about}
#df = pd.DataFrame({"name": stock_names, "url": stock_urls, "about": stock_about})
df = pd.DataFrame.from_dict(dico)
My output:
ValueError: All arrays must be of the same length
CodePudding user response:
Lazy fix: