I have the following datframe setup:
dic = {'customer_id': [102, 102, 105, 105, 110, 110, 111],
'product':['skateboard', 'skateboard', 'skateboard', 'skateboard', 'shoes', 'skateboard', 'skateboard'],
'brand': ['Vans', 'Converse', 'Vans', 'Converse', 'Converse','Converse', 'Vans'],
'membership': ['member', 'not-member', 'not-member', 'not-member', 'member','not-member', 'not-member']}
df = pd.DataFrame(dic)
Requirement: I need to drop rows where membership 'not-member' at customer_id and product granularity if the customer is a 'member' of any brand.
For example, in the above dataframe, we drop customer '102' with product 'skateboard' where membership is 'not-member' because they are already a member of a brand (Vans). We do not drop 105 because they are not a member of any brand. We do not drop 110 because the products are different.
So, the output should look like the following:
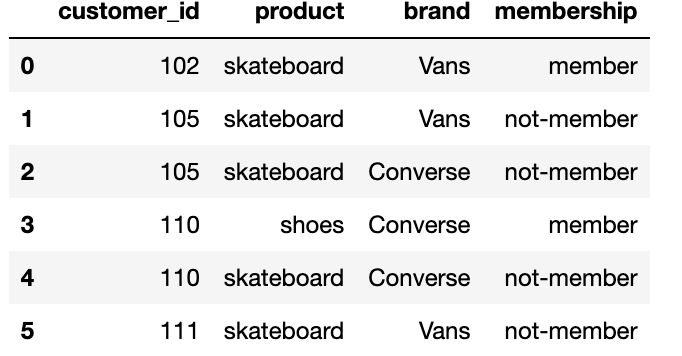
My approach: First to make a list of unique customer_id product (ex: 102_skateboard). Then loop over the list, then filter out the dataframe on unique customer-product pairs, then check if the dataframe contains membership, if true then drop not-member rows. This gives me the expected output but I was wondering if there was a better way to do it.
df['customer_product'] = df['customer_id'].astype(str) '_' df['product']
unique_customer_product = df['customer_product'].unique()
for pair in unique_customer_product:
filtered_df = df[df['customer_product'] == pair]
if 'member' in filtered_df['membership'].values:
df = df.drop(df[(df.customer_product == pair) & (df.membership == 'not-member')].index)
CodePudding user response:
df['row'] = True
def my_func(x):
aaa = x[x['membership'] == 'not-member']
if len(x[x['membership'] == 'member']) > 0 and len(aaa) > 0:
df.loc[aaa.index, 'row'] = False
df.groupby(['customer_id', 'product']).apply(my_func)
df = df[df['row']].reset_index().drop(['index', 'row'], axis=1)
print(df)
Output
customer_id product brand membership
0 102 skateboard Vans member
1 105 skateboard Vans not-member
2 105 skateboard Converse not-member
3 110 shoes Converse member
4 110 skateboard Converse not-member
5 111 skateboard Vans not-member
Here is where the 'row' helper column is created. Rows are grouped by columns 'customer_id', 'product', rows are passed to apply, which calls the my_func function. There is a check in the function: there must be values 'not-member' and 'member'. If so, use loc to set False for "not a member".
CodePudding user response:
Here is one way to do it:
df = df.sort_values(by=["customer_id", "product", "brand", "membership"])
df = pd.concat(
[
df.loc[df["customer_id"] == idx, :].drop_duplicates(["product"], keep="last")
if not df.loc[df["customer_id"] == idx, :]
.drop_duplicates(["product"], keep="last")
.pipe(lambda df_: df_.loc[df_["membership"] == "member", :])
.empty
else df.loc[df["customer_id"] == idx, :]
for idx in df["customer_id"].unique()
],
).sort_values(["customer_id", "brand"], ascending=[True, False], ignore_index=True)
Then:
print(df)
# Output
customer_id product brand membership
0 102 skateboard Vans member
1 105 skateboard Vans not-member
2 105 skateboard Converse not-member
3 110 shoes Converse member
4 110 skateboard Converse not-member
5 111 skateboard Vans not-member
CodePudding user response:
Make a helper boolean column is_member and then it's pretty straighforward to express the condition.
df['is_member'] = df.membership.eq('member')
drop_mask = (
~df['is_member']
& df.groupby(['customer_id', 'product'])['is_member'].transform('any')
)
df = df.loc[~drop_mask].reset_index(drop=True)