Can you please help me with the following issue. Imagine, I have a following df:
data = {
'A':['A1, B2, C', 'A2, A9, C', 'A3', 'A4, Z', 'A5, A1, Z'],
'B':['B1', 'B2', 'B3', 'B4', 'B4'],
}
df = pd.DataFrame(data)
How can I create a list with unique value that are stored in column 'A'? I want to smth like this:
list_A = [A1, B2, C, A2, A9, A3, A4, Z, A5]
CodePudding user response:
Assuming you define as "values" the comma separated substrings, you can 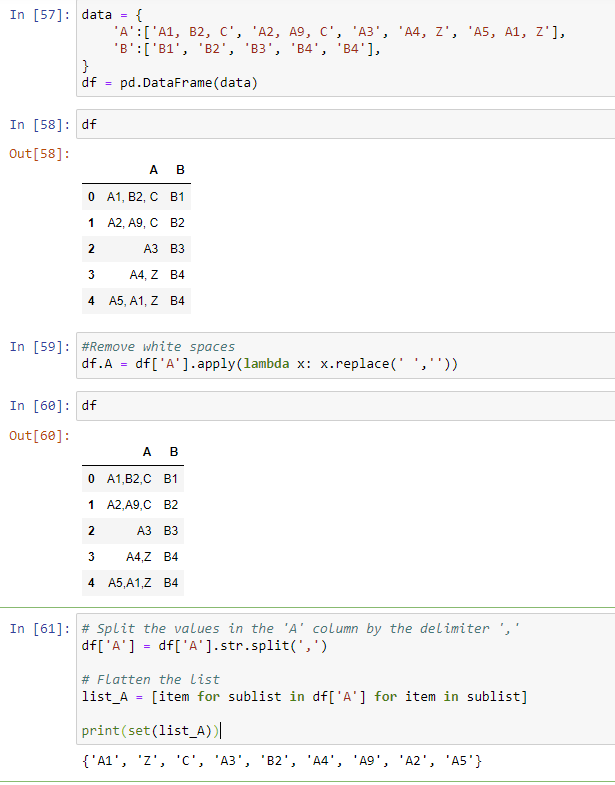 The code applies a lambda function to the 'A' column to remove any white spaces from the strings in the lists.
The code applies a lambda function to the 'A' column to remove any white spaces from the strings in the lists.
Next, the code uses the str.split() method to split the strings in the 'A' column by the delimiter ',', resulting in a columns of lists.
Finally, the code uses a list comprehension to flatten the list of lists into a single list, and then uses the set() function to create a set object containing the unique elements of the list. The set object is then printed to the console.