I have a question about formatting the output in a report that I get from csv that was spooled from SQL*Plus. I have Initial table whose data looks like this:
| ord_no | ls_prod_division | ls_prod_area | ls_prod_family_name | ls_prod_family_code | ls_prod_generic_name | ls_brand_name | ls_reference_prod | ls_description | ls_atc_code | ls_atc_desc | ls_indication | ls_ind_meddra_lvl | ls_ind_meddra_ver | ls_ind_meddra_code | ls_cindication | ls_psur_int_birthday | ls_dsur_int_birth_date | ls_eu_birth_date | ls_psur_reference_date | ls_psur_type | ls_psur_sub_freq_value | ls_psur_sub_freq_unit | ls_date_psur_start | ls_date_psur_end | ls_psur_subm_due_date |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 1.5% w/w cream | M01AB16 | aceclofenac | Analgesic & Anti-inflammatory | ||||||||||||||||||
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 100 mg tablets | M01AB16 | aceclofenac | NSAIDS | ||||||||||||||||||
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 100 mg tablets | M01AB16 | aceclofenac | Anti-inflammatory | ||||||||||||||||||
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 100 mg tablets | M01 | ANTIINFLAMMATORY AND ANTIRHEUMATIC PRODUCTS | Antiinflammatory |
And I am trying to format the report output of that table so I get it like this:
| ord_no | ls_prod_division | ls_prod_area | ls_prod_family_name | ls_prod_family_code | ls_prod_generic_name | ls_brand_name | ls_reference_prod | ls_description | ls_atc_code | ls_atc_desc | ls_indication | ls_ind_meddra_lvl | ls_ind_meddra_ver | ls_ind_meddra_code | ls_cindication | ls_psur_int_birthday | ls_dsur_int_birth_date | ls_eu_birth_date | ls_psur_reference_date | ls_psur_type | ls_psur_sub_freq_value | ls_psur_sub_freq_unit | ls_date_psur_start | ls_date_psur_end | ls_psur_subm_due_date |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 1.5% w/w cream | M01AB16 | aceclofenac | Analgesic & Anti-inflammatory | ||||||||||||||||||
| 1 | Aceclofenac 100 mg tablets | M01 | ANTIINFLAMMATORY AND ANTIRHEUMATIC PRODUCTS | NSAIDS | |||||||||||||||||||||
| 1 | Anti-inflammatory | ||||||||||||||||||||||||
| 1 | Antiinflammatory |
I am using the following code:
set colsep '|'
set trimspool on
set termout off
set echo off
set trim on
set heading on
set feedback off
set linesize 32000
set trimout on
set pagesize 50000
set underline off
col ord_no format 99999
col ls_prod_area format a200
col ls_prod_family_name format a200
col ls_prod_family_code format a200
col ls_prod_generic_name format a200
col ls_brand_name format a200
col ls_reference_prod format a200
col ls_description format a200
col ls_atc_code format a200
col ls_atc_desc format a200
col ls_indication format a200
col ls_ind_meddra_lvl format a200
col ls_ind_meddra_ver format a200
col ls_ind_meddra_code format a200
spool export.csv
break on ls_prod_area on ls_prod_family_name on ls_prod_generic_name on ls_atc_code on ls_atc_desc on ls_brand_name on ls_indication
SELECT rpad(ord_no, 200, ' ') ord_no ,rpad(ls_prod_area, 200, ' ') ls_prod_area ,rpad(ls_prod_family_name, 200, ' ') ls_prod_family_name ,rpad(ls_prod_family_code, 200, ' ') ls_prod_family_code ,rpad(ls_prod_generic_name, 200, ' ') ls_prod_generic_name ,rpad(ls_brand_name, 200, ' ') ls_brand_name ,rpad(ls_reference_prod, 200, ' ') ls_reference_prod,rpad(ls_description, 200, ' ') ls_description ,rpad(ls_atc_code, 200, ' ') ls_atc_code ,rpad(ls_atc_desc, 200, ' ') ls_atc_desc ,rpad(ls_indication, 200, ' ') ls_indication ,rpad(ls_ind_meddra_lvl, 200, ' ') ls_ind_meddra_lvl ,rpad(ls_ind_meddra_ver, 200, ' ') ls_ind_meddra_ver ,rpad(ls_ind_meddra_code, 200, ' ') ls_ind_meddra_code
from tmp_product_family
order by ord_no, ls_brand_name,LS_ATC_CODE, LS_ATC_DESC, LS_INDICATION, LS_IND_MEDDRA_LVL, LS_IND_MEDDRA_VER, LS_IND_MEDDRA_CODE ;
And I don't have a problem with output in CMD window, but with transforming the CSV to Excel via Excel's Data From Text/CSV tool. I am putting custom delimiter which is set to '|'.
And for the first ord_no (1) first and second row that were transformed from CSV to Excel looks like this:
| ORD_NO | LS_PROD_AREA | LS_PROD_FAMILY_NAME | LS_PROD_FAMILY_CODE | LS_PROD_GENERIC_NAME | LS_BRAND_NAME | LS_REFERENCE_PROD | LS_DESCRIPTION | LS_ATC_CODE | LS_ATC_DESC | LS_INDICATION | LS_IND_MEDDRA_LVL | LS_IND_MEDDRA_VER | LS_IND_MEDDRA_CODE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Medicinal Product | Aceclofenac | Aceclofenac | Aceclofenac 1.5% w/w cream | M01AB16 | aceclofenac | Analgesic & Anti-inflammatory | ||||||
| 1 | Aceclofenac 100 mg tablets | M01 | ANTIINFLAMMATORY AND ANTIRHEUMATIC PRODUCTS | Antiinflammatory |
As you can see in second row all the values after the ord_no are shifted three columns to the left (e.g. Aceclofenac 100 mg tablets should be in LS_BRAND_NAME column).
Does anyone have any idea how to escape that problem.
CodePudding user response:
As you asked about break, this is what I meant.
An ordinary query, where all "cells" are populated with data:
SQL> select d.dname, e.job, e.ename, e.sal
2 from emp e join dept d on d.deptno = e.deptno
3 order by d.dname, e.job;
DNAME JOB ENAME SAL
-------------- --------- ---------- ----------
ACCOUNTING CLERK MILLER 1300
ACCOUNTING MANAGER CLARK 2450
ACCOUNTING PRESIDENT KING 5000
RESEARCH ANALYST SCOTT 3000
RESEARCH ANALYST FORD 3000
RESEARCH CLERK ADAMS 1100
RESEARCH CLERK SMITH 840
RESEARCH MANAGER JONES 2975
SALES CLERK JAMES 950
SALES MANAGER BLAKE 2850
SALES SALESMAN MARTIN 1250
SALES SALESMAN WARD 1250
SALES SALESMAN ALLEN 1600
SALES SALESMAN TURNER 1500
14 rows selected.
If you put a break on e.g. department name and job, you get something that looks like result you need:
SQL> spool stefek.csv
SQL> break on dname on job
SQL> select d.dname, e.job, e.ename, e.sal
2 from emp e join dept d on d.deptno = e.deptno
3 order by d.dname, e.job;
DNAME JOB ENAME SAL
-------------- --------- ---------- ----------
ACCOUNTING CLERK MILLER 1300
MANAGER CLARK 2450
PRESIDENT KING 5000
RESEARCH ANALYST SCOTT 3000
FORD 3000
CLERK ADAMS 1100
SMITH 840
MANAGER JONES 2975
SALES CLERK JAMES 950
MANAGER BLAKE 2850
SALESMAN MARTIN 1250
WARD 1250
ALLEN 1600
TURNER 1500
14 rows selected.
SQL> spool off
SQL>
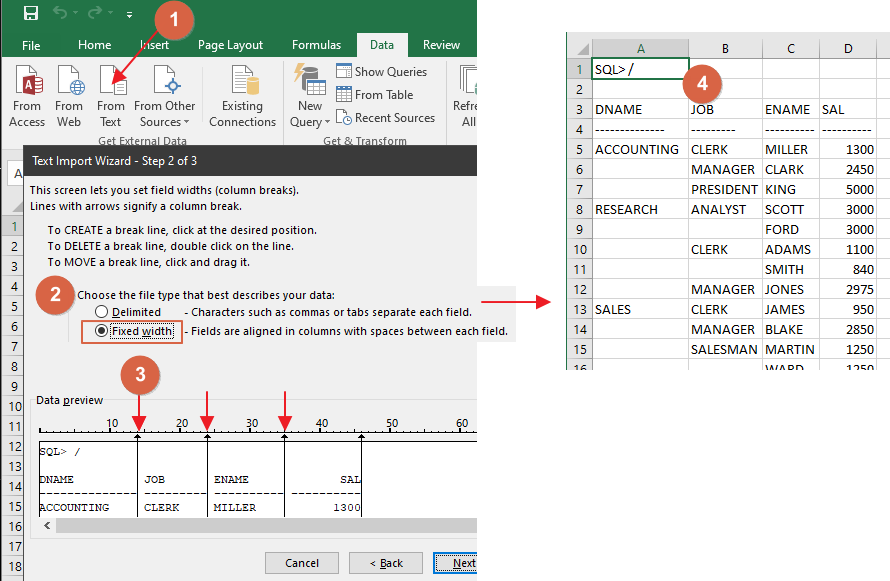
If you open that file in Excel, you get this:
- in ver. 2016, go to "Data - From text" and follow the wizard
- choose "Fixed width"
- move separator lines where necessary
- see the result
Connecting to SQL*Plus
You should know username, password and database you're connecting to. For example, I'm scanning my TNSNAMES.ORA file with the mctnsping utility (written by Michel Cadot; it doesn't require Oracle client to work. You can find it on OraFAQ Forum). Or, if you have TNSPING available, use it:
C:\Temp>mctnsping orcl
McTnsping Utility by Michel Cadot: Version 2021.12.03 on 20-PRO-2022 14:09:02
Copyright (c) Michel Cadot, 2016-2021. All rights reserved.
Using ping version 11
Used parameter files:
C:\Users\littlefoot\Documents\sqlnet.ora
C:\Users\littlefoot\Documents\tnsnames.ora
Found tnsnames.ora entry:
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=db_orcl)(PORT=1521))(CONNECT_DATA=(SID=orcl)))
Attempting to contact db_orcl:1521
OK (46 msec)
Now, use data you gathered; connect string is in format of @database_server:port/service_name:
C:\Temp>sqlplus scott/tiger@db_orcl:1521/orcl
SQL*Plus: Release 18.0.0.0.0 - Production on Uto Pro 20 14:09:17 2022
Version 18.5.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
SQL> select * from dual;
D
-
X
SQL>
CodePudding user response:
If you have the minimal sample data:
CREATE TABLE table_name (a, b, c, d ) AS
SELECT 'A1', 'B1', 'C1', 'D1' FROM DUAL UNION ALL
SELECT 'A2', 'B1', 'C2', 'D1' FROM DUAL UNION ALL
SELECT 'A3', 'B2', 'C2', 'D1' FROM DUAL UNION ALL
SELECT 'A4', 'B3', 'C2', 'D1' FROM DUAL;
and you want to shuffle the data up the rows so that duplicates are not displayed then you can rank the values in each column, unpivot and then re-pivot the data:
SELECT a, b, c, d
FROM (
SELECT a, b, c, d,
DENSE_RANK() OVER (ORDER BY a) AS a_rnk,
DENSE_RANK() OVER (ORDER BY b) AS b_rnk,
DENSE_RANK() OVER (ORDER BY c) AS c_rnk,
DENSE_RANK() OVER (ORDER BY d) AS d_rnk
FROM table_name
)
UNPIVOT (
(value, rnk) FOR key IN (
(a, a_rnk) AS 'A',
(b, b_rnk) AS 'B',
(c, c_rnk) AS 'C',
(d, d_rnk) AS 'D'
)
)
PIVOT (
MAX(value) FOR key IN ('A' AS a, 'B' AS b, 'C' AS c, 'D' AS d)
)
ORDER BY rnk
Which outputs:
| A | B | C | D |
|---|---|---|---|
| A1 | B1 | C1 | D1 |
| A2 | B2 | C2 | null |
| A3 | B3 | null | null |
| A4 | null | null | null |