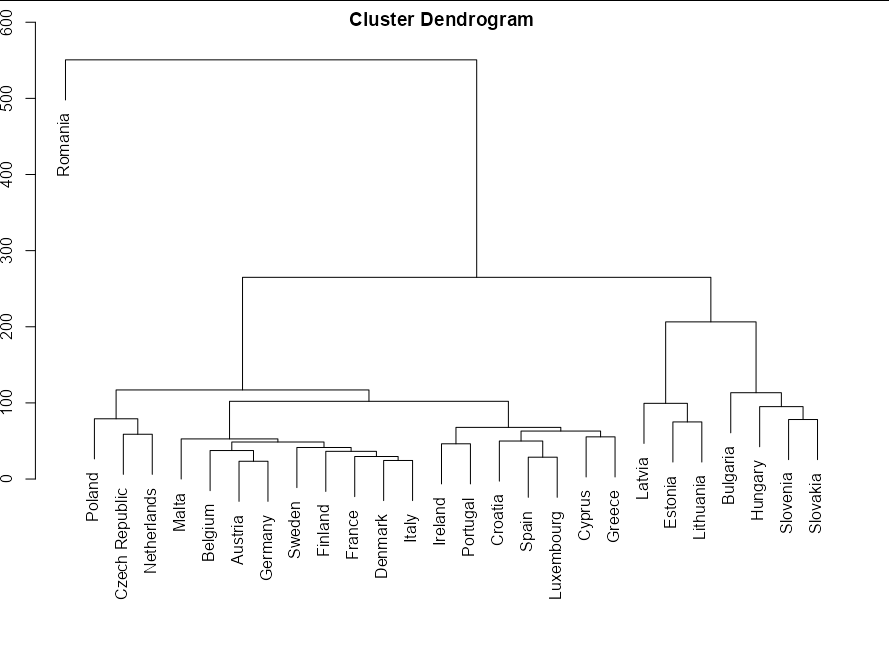
I want to perform dendrogram visualization using hierarchical grouping with Minkowski method on my dataset from eurostat library. I want to make values shown in this dendrogram:
 to display country names like in this one
to display country names like in this one
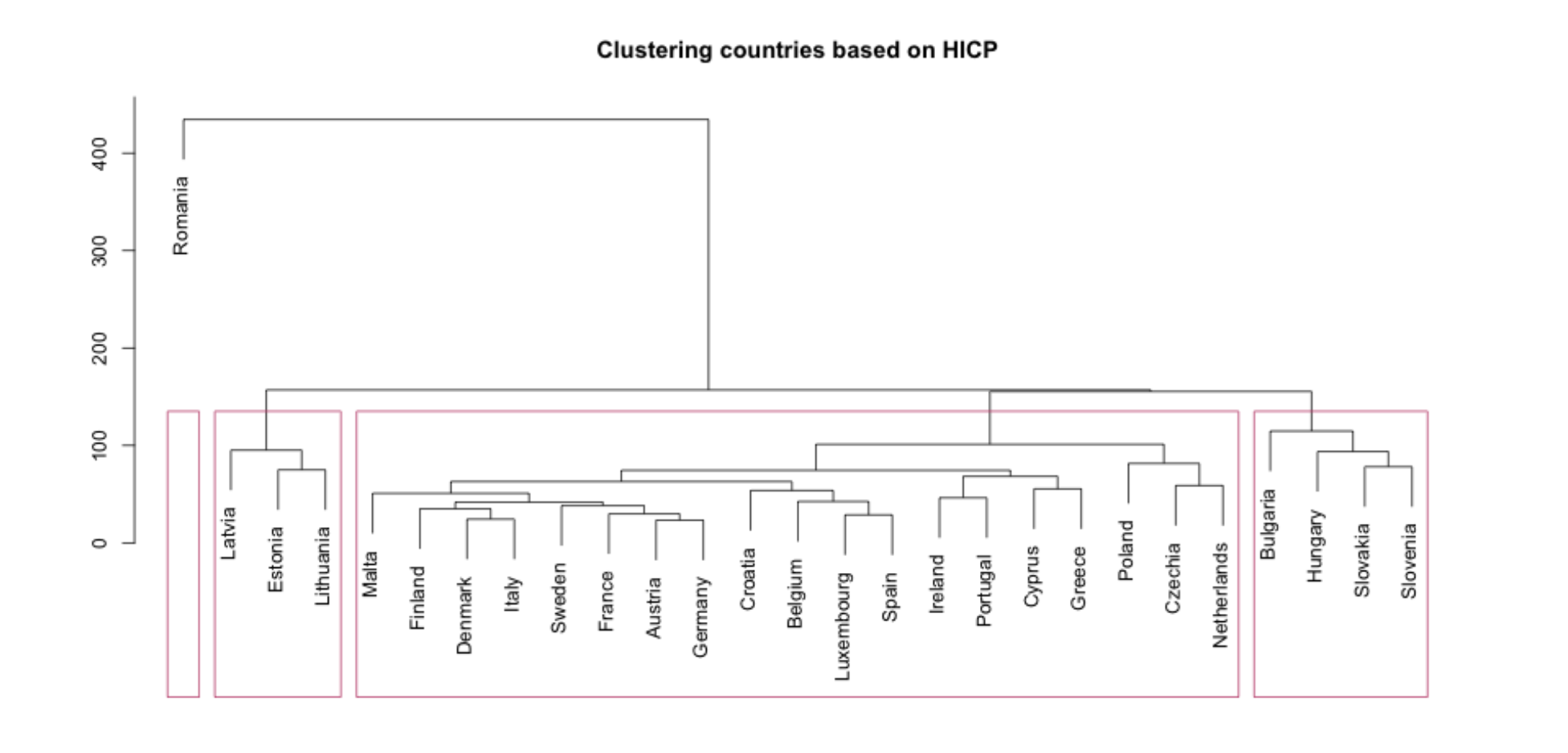 . I can only use base R packages and/or ggplot2 due to project's requirements
. I can only use base R packages and/or ggplot2 due to project's requirements
Use this code to recreate my situation:
install.packages("eurostat")
install.packages("dplyr")
install.packages("ggplot2")
library(eurostat)
library(dplyr)
library(ggplot2)
member_states <- c("AT", "BE", "BG", "HR", "CY", "CZ",
"DK", "EE", "FI", "FR", "DE", "GR",
"HU", "IE", "IT", "LV", "LT", "LU",
"MT", "NL", "PL", "PT", "RO", "SK",
"SI", "ES", "SE", "EL")
hicp <- get_eurostat("prc_hicp_manr", time_format = "date")
hicp_filtered <- hicp %>% filter(time >= as.Date("2000-02-01")
& time <= as.Date("2022-09-01")) %>%
filter(coicop == "CP00") %>%
filter(geo %in% member_states) %>%
mutate(geo = case_when(
geo == "AT" ~ "Austria",
geo == "BE" ~ "Belgium",
geo == "BG" ~ "Bulgaria",
geo == "HR" ~ "Croatia",
geo == "CY" ~ "Cyprus",
geo == "CZ" ~ "Czech Republic",
geo == "DK" ~ "Denmark",
geo == "EE" ~ "Estonia",
geo == "FI" ~ "Finland",
geo == "FR" ~ "France",
geo == "DE" ~ "Germany",
geo == "GR" ~ "Greece",
geo == "HU" ~ "Hungary",
geo == "IE" ~ "Ireland",
geo == "IT" ~ "Italy",
geo == "LV" ~ "Latvia",
geo == "LT" ~ "Lithuania",
geo == "LU" ~ "Luxembourg",
geo == "MT" ~ "Malta",
geo == "NL" ~ "Netherlands",
geo == "PL" ~ "Poland",
geo == "PT" ~ "Portugal",
geo == "RO" ~ "Romania",
geo == "SK" ~ "Slovakia",
geo == "SI" ~ "Slovenia",
geo == "ES" ~ "Spain",
geo == "SE" ~ "Sweden",
geo == "EL" ~ "Greece",
TRUE ~ geo
))
data <- hicp_filtered[, c(3,4,5)]
data_widened <- reshape(transform(data,
id = ave(seq_along(geo), geo, FUN = seq_along)),
idvar = c("id", "time"),
direction = "wide", timevar = "geo")
To perform that classification analysis I tried to write this code:
distance_matrix <- dist(data_widened[3:29, ], method = "minkowski", p = 1.5)
hc <- hclust(distance_matrix, method = "ward.D2")
plot(hc)
How can I replace those weird values with country names and allign clusters on my plot too look like in the desired form? Thanks in advance.
CodePudding user response:
There are 2 options here. Use the labels option in the plot() function or define the row names.
Since this is a university assignment, I'll demonstrate with an abridged "mtcars" dataset.
#test data set.
data_widened <-structure(list(mpg = c(21, 21, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.2, 17.8, 16.4, 17.3, 15.2, 10.4),
disp = c(160, 160, 108, 258, 360, 225, 360, 146.7, 140.8, 167.6, 167.6, 275.8, 275.8, 275.8, 472),
hp = c(110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, 180, 180, 205),
drat = c(3.9, 3.9, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.92, 3.92, 3.07, 3.07, 3.07, 2.93),
wt = c(2.62, 2.875, 2.32, 3.215, 3.44, 3.46, 3.57, 3.19, 3.15, 3.44, 3.44, 4.07, 3.73, 3.78, 5.25),
qsec = c(16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20, 22.9, 18.3, 18.9, 17.4, 17.6, 18, 17.98),
Names = c("Mazda RX4", "Mazda RX4 Wag", "Datsun 710", "Hornet 4 Drive", "Hornet Sportabout", "Valiant", "Duster 360",
"Merc 240D", "Merc 230", "Merc 280", "Merc 280C", "Merc 450SE", "Merc 450SL", "Merc 450SLC", "Cadillac Fleetwood")),
row.names = c(NA,15L), class = "data.frame")
#define the row names to match the desired labels
rownames(data_widened) <- data_widened$Names
#cluster
distance_matrix <- dist(data_widened[ , 1:6], method = "minkowski", p = 1.5)
hc <- hclust(distance_matrix, method = "ward.D2")
#plot
plot(hc)
# or this if the row names are not defined.
plot(hc, labels=data_widened$Names)
CodePudding user response:
You have got the row and column indices round the wrong way, and you also need to transpose the data.
# Remove "values." from the names of each column
names(data_widened) <- gsub("values\\.", "", names(data_widened))
distance_matrix <- dist(t(data_widened[,3:29]), method = "minkowski", p = 1.5)
hc <- hclust(distance_matrix, method = "ward.D2")
plot(hc)