i have data that looks like this:
snp=c(10139833,10139832,10139834,10139835)
code_0=c(7,7,5,4)
code_1=c(3,5,5,5)
df=data.frame(snp,code_0,code_1)
what i whish to do it to plot the distribution if code_0 and code_1 : how many times does each value in code_0 and code_1 occur: in code_0 value 7 occurs 2 times , 5 ome time anf 4 one time same for code_1 both i want in the same plot (code_0 and code_1 in different colors) i trid to do hist function or barplot but it didnt produce the correct results or just returned an error . is there any way i can make it work in R? THANK YOU
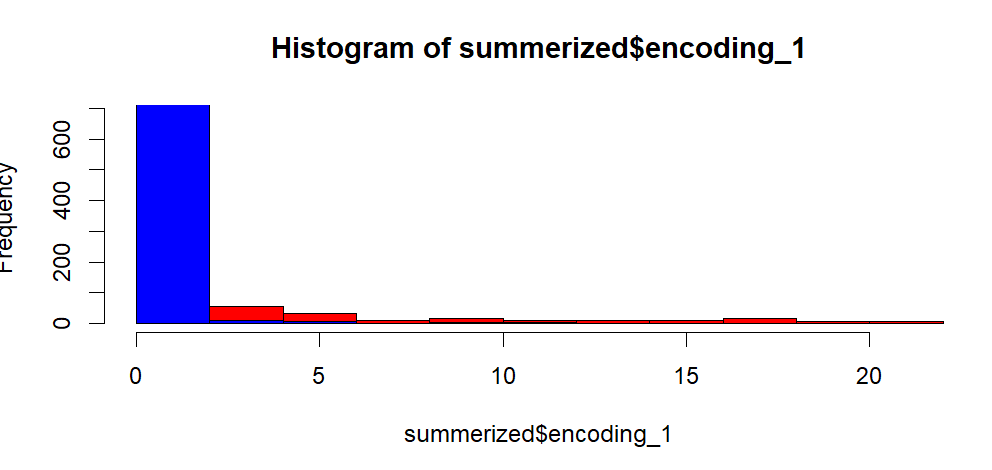
i tried this :
hist(summerized$encoding_1
,
col = "red",
)
> hist(summerized$encoding_2,
col = "blue",
add = TRUE)
which produced :
CodePudding user response:
This might be what you are looking for.
library(tidyverse)
snp=c(10139833,10139832,10139834,10139835)
code_0=c(7,7,5,4)
code_1=c(3,5,5,5)
df=data.frame(snp,code_0,code_1)
df %>%
pivot_longer(cols = code_0:code_1,
names_to = "code",
values_to = "values") %>%
ggplot(aes(x=values))
geom_histogram()
facet_wrap(~code)
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
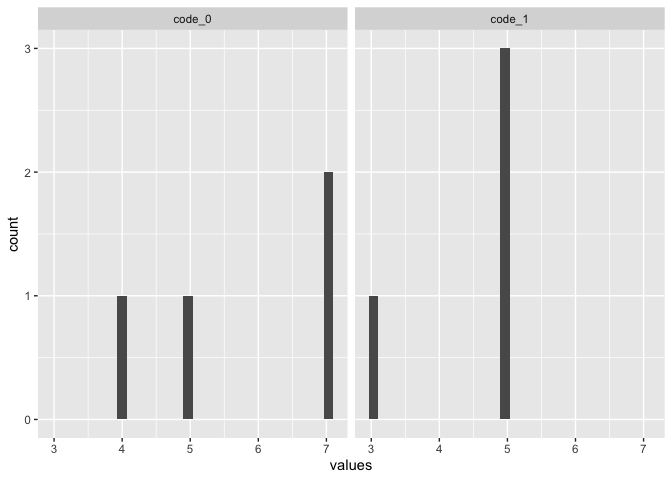
Created on 2022-12-26 with reprex v2.0.2
Edit: Here the code for plotting the histogram in one plot.
library(tidyverse)
snp=c(10139833,10139832,10139834,10139835)
code_0=c(7,7,5,4)
code_1=c(3,5,5,5)
df=data.frame(snp,code_0,code_1)
df %>%
pivot_longer(cols = code_0:code_1,
names_to = "code",
values_to = "values") %>%
ggplot(aes(x=values, fill=code))
geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
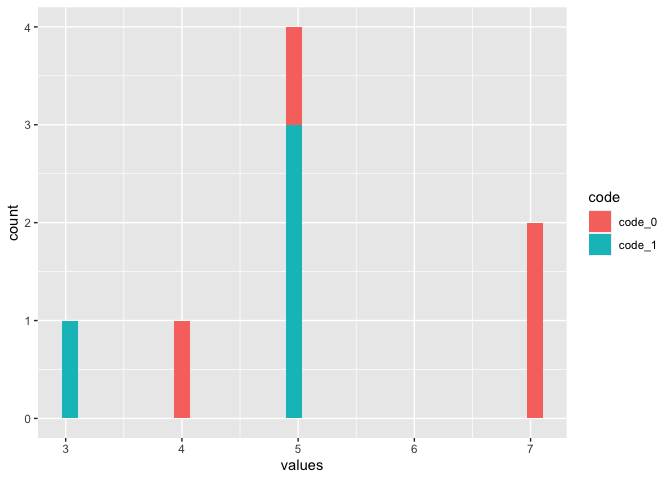
Created on 2022-12-26 with reprex v2.0.2