I have a pyspark dataframe in the below format
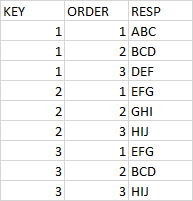 I
I
I am tring to create a pyspark dataframe in the below format

I tried doing this by splitting the source dataframe into three by filtering on order value (1,2,3 these are present for the every key) and joined them using a left join using key and was able to get the dataframe in required format.
But is there any better way to solve this in pyspark?
Thanks in advance!
CodePudding user response:
Your ORDER1, ORDER2 and ORDER3 columns are a bit redundant. If you can live without them, you can combine a groupBy and pivot like so:
from pyspark.sql.functions import collect_list
df = spark.createDataFrame(
[
(1, 1, "ABC"),
(1, 2, "BCD"),
(1, 3, "DEF"),
(2, 1, "EFG"),
(2, 2, "GHI"),
(2, 3, "HIJ"),
(3, 1, "EFG"),
(3, 2, "BCD"),
(3, 3, "HIJ"),
],
["KEY", "ORDER", "RESP"]
)
output = df.groupBy("KEY").pivot("ORDER").agg(collect_list("RESP"))
output.show()
--- ----- ----- -----
|KEY| 1| 2| 3|
--- ----- ----- -----
| 1|[ABC]|[BCD]|[DEF]|
| 2|[EFG]|[GHI]|[HIJ]|
| 3|[EFG]|[BCD]|[HIJ]|
--- ----- ----- -----
I'm using collect_list to make sure that if you have more than 1 RESP value for specific combination of KEY and ORDER, that you don't lose it but it just gets put inside of an array. So all the values that you're seeing in this dataframe are arrays (with 1 element for your example).
If you're sure you only have 1 value for a combination of KEY and ORDER and you don't want arrays as values, you can also use first() instead of collect_list():
from pyspark.sql.functions import first
...
output = df.groupBy("KEY").pivot("ORDER").agg(first("RESP"))
output.show()
--- --- --- ---
|KEY| 1| 2| 3|
--- --- --- ---
| 1|ABC|BCD|DEF|
| 2|EFG|GHI|HIJ|
| 3|EFG|BCD|HIJ|
--- --- --- ---