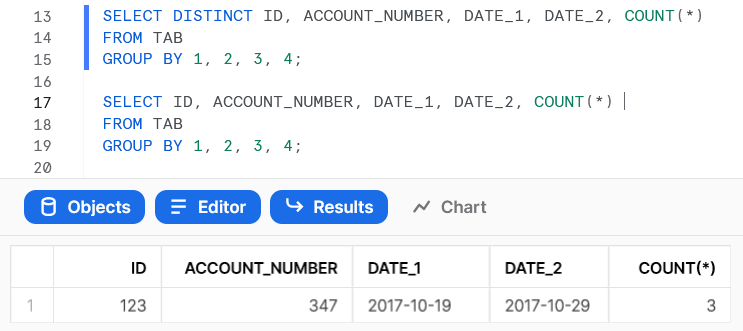
Below is a row from a SnowFlake query. This is the only row in the result with this information (i.e., this row is unique).
ID ACCOUNT_NUMBER DATE_1 DATE_2
123 347 2017-10-19 2017-10-29
I ran a GROUP BY like below to count the number of rows in each group. I got 3 for the above row. Shouldn't I get 1?
SELECT DISTINCT ID, ACCOUNT_NUMBER, DATE_1, DATE_2, COUNT(*)
FROM TABLE GROUP BY 1, 2, 3, 4;
ID ACCOUNT_NUMBER DATE_1 DATE_2 COUNT
123 347 2017-10-19 2017-10-29 3
I expected to see count of 1 for this row, but I got 3.
CodePudding user response:
The result is correct. The DISTINCT is applied after the grouping and has not effect in provided query.
To apply DISTINCT it should be provided before grouping(subquery)
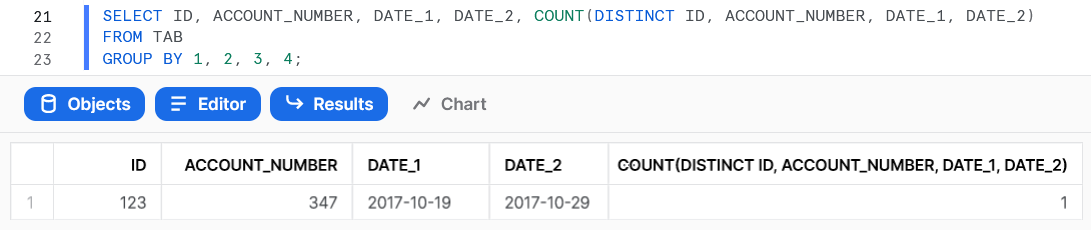
SELECT ID, ACCOUNT_NUMBER, DATE_1, DATE_2, COUNT(*) FROM (SELECT DISTINCT ID, ACCOUNT_NUMBER, DATE_1, DATE_2 FROM TAB) GROUP BY 1, 2, 3, 4;or as a part of aggregate function:
SELECT ID, ACCOUNT_NUMBER, DATE_1, DATE_2, COUNT(DISTINCT ID, ACCOUNT_NUMBER, DATE_1, DATE_2) FROM TAB GROUP BY 1, 2, 3, 4;
For sample data:
CREATE OR REPLACE TABLE TAB(ID INT, ACCOUNT_NUMBER INT, DATE_1 TEXT, DATE_2 TEXT) AS SELECT 123, 347, '2017-10-19', '2017-10-29' UNION ALL SELECT 123, 347, '2017-10-19', '2017-10-29' UNION ALL SELECT 123, 347, '2017-10-19', '2017-10-29';