I have 2 Panda Data Frames.
For example:
First Data Frame with
Student IDandStudents Nameof 100 students.Second Data Frame also with
Student IDandStudents Nameof 20 students. These 20 students are also in the First Data Frame. I need the remaining 80 students in another Data Frame?
Which function can I use?
Is pd.merge able to solve this?
CodePudding user response:
Let me simplify your first DF to 3 students, and second DF to 1 student.
df1 = pd.DataFrame({"ID":[1, 2, 3], "Name":["a", "b", "c"]})
df2 = pd.DataFrame({"ID":[3], "Name":["c"]})
new_df = pd.concat([df1, df2]).drop_duplicates(keep=False)
pd.concat will concatenate dataframes, and use drop_duplicates(keep=False) to remove duplicate values.
CodePudding user response:
Another way to do it is by selecting student names and IDs by filtering the first data frame for rows that do not exist on the second data frame.
To generate the test data, I'm using a package called names. Since you already have both data frames, you don't have to import the names package like I did, nor define the "dummy" test data. These parts were created solely to test the implementation. In other words, you can skip directly to the "Problem Solution" part.
The code below contains two ways to solve your problem. I've added some comments to help you understand the differences between these two solutions.
# == Necessary Imports =========================================================
# Uncoment the line that starts with `!pip`, to install the `names` package.
# You don't have to install this library, since you already have the student
# names. This package can generate random names, and is only used to
# create some "dummy" data to test our solution.
# NOTE: if you're running this code outside a Jupyter notebook,
# remove the `!` from the `pip install` command before running it.
# The `!` sign enables you to run terminal commands from within Jupyter
# and is not required if you're not running this code inside a Jupyter notebook.
# !pip install names
import pandas as pd
import numpy as np
# This next import is only needed to generate some dummy test data. Since you'll
# be using real data that already exists, you don't have to import the `names`
# package. Therefore, you can comment this line.
import names
# == Creating Dummy Data =======================================================
# You don't have to execute these next few lines of code that are being used
# to create the `df` and `df2` data frames. They're only used to create some
# data to show how you could solve your problem.
#
# In order to test our implementation, we'll Generate 2 data frames that have
# 2 columns: `'Students Name'` and `'Student ID'`. The first data frame (`df`)
# will have 100 rows with unique names and IDs. The second data frame (`df2`)
# will contain 20 of these 100 rows from the first data frame.
# To generate the names, we'll be using the `names.get_full_name()` function.
# For the IDs, we'll use the range function, that yields monotonically
# increasing numbers from 0 to 99.
# Number of rows to be generated.
nrows = 100
df = pd.DataFrame(
{
'Student ID': range(nrows),
'Students Name': [names.get_full_name() for _ in range(nrows)],
}
)
# To create the second data frame, that contains the names and IDs of 20 students
# from the first data frame we've just defined, we'll use the `numpy.random.choice`
# function, that enables us to select a certain amount of names with or without
# repeating values. In this case, we'll set `replace=False` to avoid selecting
# the same name multiple times. Then, we'll merge this new data frame with the
# original data, to obtain these 20 students ID as well.
# Finally, we'll sort values by ID just to organize students by ID in an ascending
# order, like the first data frame does. This last step is optional and does not
# impact the end results.
df2 = pd.DataFrame(
{'Students Name': np.random.choice(df['Students Name'], replace=False, size=20)}
).merge(df, on='Students Name', how='inner').sort_values('Student ID')
# == Problem Solution ==========================================================
# I'm assuming you're looking for the names and IDs of students that exist on
# the first data frame that holds the 100 students, but do not exist on the
# second data frame that contains the information of 20 out of these 100
# students.
# -- OPTION 1 ------------------------------------------------------------------
# This option selects the students that are on the first Data Frame and not on
# the second data frame, based on the ID of each student.
# This solution won't work if you have data frames that assigns different IDs
# for the same student. In these cases, you might consider using the
# 'OPTION 2' approach instead.
result = df[~df['Student ID'].isin(df2['Student ID'])]
# Checking whether the `result` data frame contains the information about
# 80 students, as expected.
print(
f'Number of students that do not exist on the second data frame: {result.shape[0]:,}'
)
# Prints:
#
# "Number of students that do not exist on the second data frame: 80"
# -- OPTION 2 ------------------------------------------------------------------
# This option selects the students that are on the first Data Frame and not on
# the second based on the name OR ID of each student.
# The `|` character signifies an OR condition, therefore it filters the data frame
# when at least one of the conditions is True.
# The `~` sign on the start of each condition represents an negation of some
# condition.
result = df[
(~df['Student ID'].isin(df2['Student ID']))
| (~df['Students Name'].isin(df2['Students Name']))
]
# Checking whether the `result` data frame contains the information about
# 80 students, as expected.
print(
f'Number of students that do not exist on the second data frame: {result.shape[0]:,}'
)
# Prints:
#
# "Number of students that do not exist on the second data frame: 80"
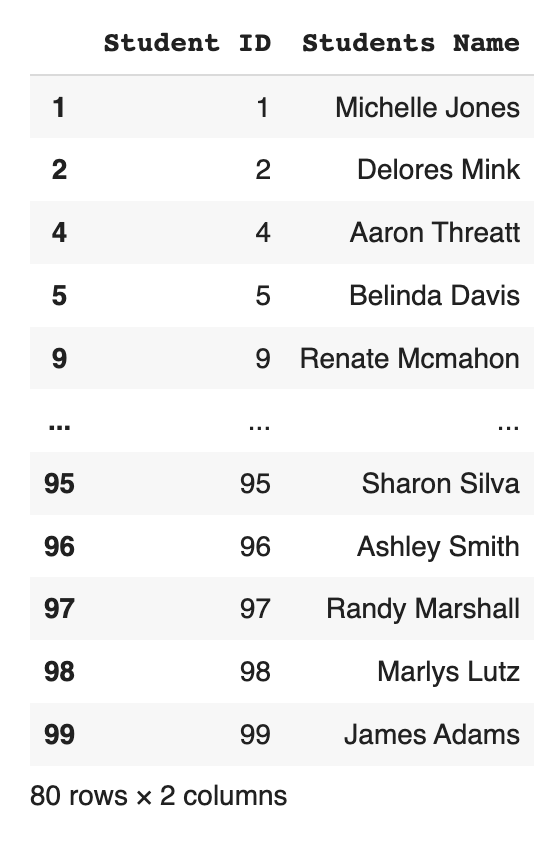
Here's how the generated result data frame from the solution looks like: