I have a dataset that looks like:
my_df = pd.DataFrame({"id": [1, 1, 1], "word": ["hello", "my", "friend"]})
And I would like to group by id and concatenate the word (without changing the order), the result dataset should look like:
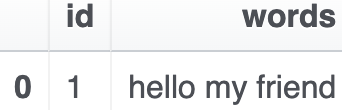
Given:
- Dataframe is already sorted by id, words in the desired order
Constraints:
- The the word order should be maintained
CodePudding user response:
This is a .groupby operation. With pandas you can pass user defined functions, to perform aggregations. In this case you just want to .join the grouped elements with a single space.
out = my_df.groupby('id', as_index=False).agg(words=('word', ' '.join))
print(out)
id words
0 1 hello my friend
as_index=Falseensures thatidremains a column (not the index) after the operation.agg(words=...)perform an aggregation on each of our groups, creating a new column titled"words"('word', ' '.join)on the column titled"word"from our grouped dataframe, apply the function' '.jointo the data. Note that you could also write this aslambda s: ' '.join(s), but I decided to go with the less verbose approach.
CodePudding user response:
If we have the following dataframe (slighyly modified from yours)
my_df = pd.DataFrame({"id": [1, 1, 1, 2, 2, 2], "word": ["hello", "my", "friend", "goodbye", "my", "friend"]})
Output
id word
0 1 hello
1 1 my
2 1 friend
3 2 goodbye
4 2 my
5 2 friend
To get the desired result, use
my_df.groupby('id')['word'].apply(lambda x: ' '.join(x))
Output
id
1 hello my friend
2 goodbye my friend
Name: word, dtype: object
This groups each row by your column id, then takes each result and uses Pandas join to join them with a whitespace delimiter.
This is a groupby object, not a dataframe though; to get it back into a useable dataframe, append reset_index
my_df.groupby('id')['word'].apply(lambda x: ' '.join(x)).reset_index()
Output
id word
0 1 hello my friend
1 2 goodbye my friend
If the dataframe is rather large, using apply may not be the best approach, as it performs the aggregation over every row; there may be faster methods to use. As long as your dataframe isn't tens of thousands of rows, the difference should be negligible.