I have a very extensive dataset with loads of employees in R that have done a certain task at a certain time. An example is given below
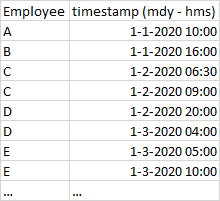
emp <- c('a','b','c','c','d','d','e','e')
timestamp <- c('1-1-2020 10:00','1-1-2020 16:00','1-2-2020 06:30','1-2-2020 09:00','1-2-2020 20:00','1-3-2020 04:00','1-3-2020 05:00','1-3-2020 10:00')
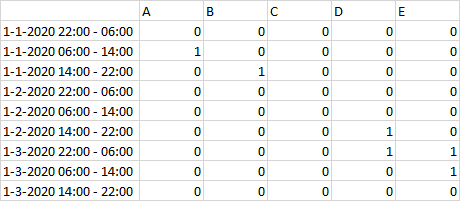
From this information I want to extract in which shift on which day the employees were at work. From the current example I should get the following:
Moreover, I would like a column next to the shift definition that states how many seconds have passed between the start of the first shift (1-1-2020 22:00 - 06:00) and the current shift. This should look like this:
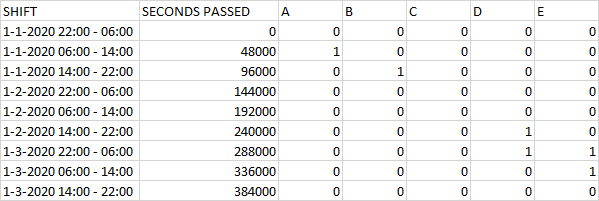
Anyone any idea how I can create such a work schedule in R? Preferably a solution using dplyr
CodePudding user response:
library(lubridate)
timestamp <- mdy_hm(timestamp)
starts <- seq(as_date(min(timestamp)) - hours(2), to = max(timestamp), by = "8 hours")
shifts <- lapply(starts, \(start) interval(start, start hours(8)))
worked_in_shift <- \(shift, timestamp) any(timestamp %within% shift)
data.frame(
shift = I(shifts),
outer(
shifts,
split(timestamp, emp),
Vectorize(worked_in_shift)
)
)
shift a b c d e
1 2019-12-.... FALSE FALSE FALSE FALSE FALSE
2 2020-01-.... TRUE FALSE FALSE FALSE FALSE
3 2020-01-.... FALSE TRUE FALSE FALSE FALSE
4 2020-01-.... FALSE FALSE FALSE FALSE FALSE
5 2020-01-.... FALSE FALSE TRUE FALSE FALSE
6 2020-01-.... FALSE FALSE FALSE TRUE FALSE
7 2020-01-.... FALSE FALSE FALSE TRUE TRUE
8 2020-01-.... FALSE FALSE FALSE FALSE TRUE
CodePudding user response:
This is an answer based on data.table. Data table has a "rolling join" feature which is very straigthfoward on this situations.
library(data.table)
# data
df <- data.frame(
emp = c('a','b','c','c','d','d','e','e'),
timestamp = c('1-1-2020 10:00','1-1-2020 16:00','1-2-2020 06:30','1-2-2020 09:00',
'1-2-2020 20:00','1-3-2020 04:00','1-3-2020 05:00','1-3-2020 10:00'))
# setting data.table
# casting timestamp as time variable
setDT(df)
df$timestamp <- as.POSIXct(strptime( df$timestamp, "%m-%d-%Y %H:%M"))
# create table of "shifts"
periods <- data.table(
SHIFT_from = seq.POSIXt( from = as.POSIXct("2019-12-31 22:00"),
to = as.POSIXct("2020-01-03 14:00"), by = "8 hours"),
SHIFT_to = seq.POSIXt( from = as.POSIXct("2020-01-01 06:00"),
to = as.POSIXct("2020-01-03 22:00"), by = "8 hours"))
# join (rolling) and calculate seconds.
df <- df[periods, .(
emp,
from = SHIFT_from,
to = SHIFT_to,
timestamp = x.timestamp,
secs = as.integer(difftime(i.SHIFT_from, i.SHIFT_from[1], units = "s"))),
on = c("timestamp" = "SHIFT_to"), roll=TRUE]
# output
dcast(df, from to secs ~ emp , fun = length)[,-"NA"]
#> from to secs a b c d e
#> 1: 2019-12-31 22:00:00 2020-01-01 06:00:00 0 0 0 0 0 0
#> 2: 2020-01-01 06:00:00 2020-01-01 14:00:00 28800 1 0 0 0 0
#> 3: 2020-01-01 14:00:00 2020-01-01 22:00:00 57600 0 1 0 0 0
#> 4: 2020-01-01 22:00:00 2020-01-02 06:00:00 86400 0 1 0 0 0
#> 5: 2020-01-02 06:00:00 2020-01-02 14:00:00 115200 0 0 1 0 0
#> 6: 2020-01-02 14:00:00 2020-01-02 22:00:00 144000 0 0 0 1 0
#> 7: 2020-01-02 22:00:00 2020-01-03 06:00:00 172800 0 0 0 0 1
#> 8: 2020-01-03 06:00:00 2020-01-03 14:00:00 201600 0 0 0 0 1
#> 9: 2020-01-03 14:00:00 2020-01-03 22:00:00 230400 0 0 0 0 1