I have a data coming from the field and I want to categorize it with a gap of specific range. I want to categorize in 100 range. That is, 0-100, 100-200, 200-300 My code:
df=pd.DataFrame([112,341,234,78,154],columns=['value'])
value
0 112
1 341
2 234
3 78
4 154
Expected answer:
value value_range
0 112 100-200
1 341 200-400
2 234 200-300
3 78 0-100
4 154 100-200
My code:
df['value_range'] = df['value'].apply(lambda x:[a,b] if x>a and x<b for a,b in zip([0,100,200,300,400],[100,200,300,400,500]))
Present solution:
SyntaxError: invalid syntax
CodePudding user response:
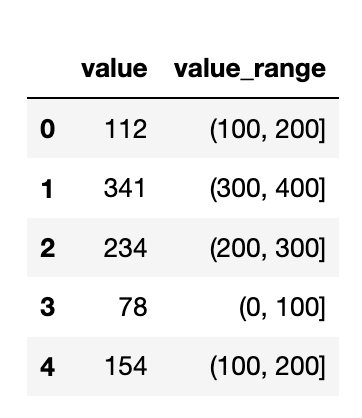
You can use pd.cut:
df["value_range"] = pd.cut(df["value"], [0, 100, 200, 300, 400], labels=['0-100', '100-200', '200-300', '300-400'])
print(df)
Prints:
value value_range
0 112 100-200
1 341 300-400
2 234 200-300
3 78 0-100
4 154 100-200
CodePudding user response:
you can use the odd IntervalIndex.from_tuples. Just set the tuple values to the values that are in your data and you should be good to go! -Listen to Lil Wayne
df = pd.DataFrame([112,341,234,78,154],columns=['value'])
bins = pd.IntervalIndex.from_tuples([(0, 100), (100, 200), (200, 300), (300, 400)])
df['value_range'] = pd.cut(df['value'], bins)