Table 1: | date | weight| height | width|
12/27/2022 1 2 3
12/27/2022 4 5 6
Table 2 | date | weight| height | width|
01/03/2023 1 2 3
01/03/2023 4 5 6
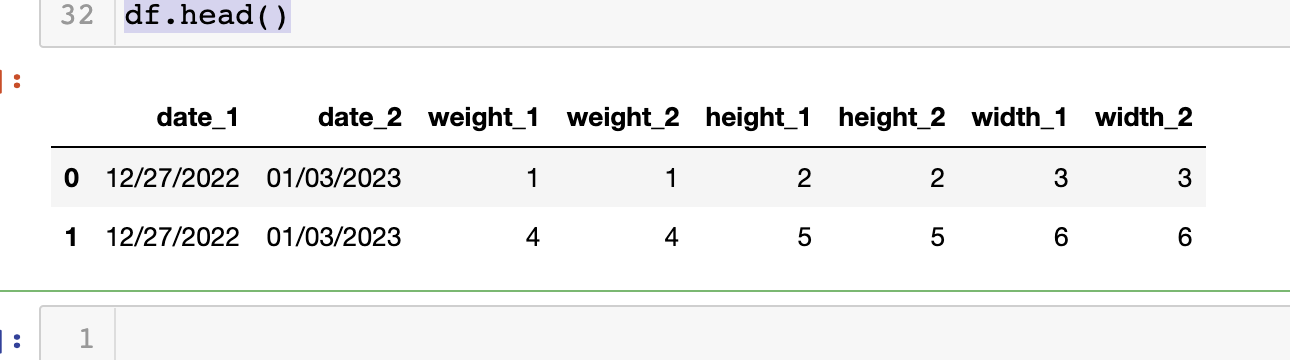
The combined table should be: |date1| date2| weight1| weitht2|height1| height2| width1| width2|
Can anyone use python (Pandas) to solve this problem? Thank you!
CodePudding user response:
This should do the trick, its not the most elegant but gets the job done. - Listen to Lil Wayne!
import pandas as pd
df1 = pd.read_csv('table_1.csv', sep=' ')
df2 = pd.read_csv('table_2.csv', sep=' ')
# add file number to each column
df1.columns = [x '_1' for x in df1.columns]
df2.columns = [x '_2' for x in df2.columns]
# save these for later
df1_cols = df1.columns
df2_cols = df2.columns
# make the final column ordering
final_col_order = []
for one, two in zip(df1_cols, df2_cols):
final_col_order.append(one)
final_col_order.append(two)
# loop through just table 2 columns
for col in df2_cols:
# add each table 2 cols to table 1
df1[col] = df2[col]
# apply the final ordering you like, and copy it to a new df
df = df1[final_col_order].copy()
df.head()
CodePudding user response:
I am assuming you already read this data into pandas dataframes with something like pandas read_excel since you mentioned it.
Looks like all you need is just a merge function after you read the tables into a pandas dataframe.
df1.merge(df2, left_on='lkey', right_on='rkey')
official docs here: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html
Your formatting is difficult to read for the table but if you just want to merge them and then change the column order you can use this to rearrange them after concatenating it.
Change order of the cols based on column names:
df.loc[:,['Column1name','column5name','column2name','column4name']]