I have a dataset that contains data in the following manner:
Name, Result, Date #A lot of other stuff as we, but these are the only relevant ones I think
Peter Parker, 150, 2018-03-03
Peter Parker, 155, 2018-03-04
Peter Parker, 156, 2018-03-05
Peter Parker, 154, 2018-03-06
Peter Parker, 158, 2018-03-07
Benny Thompson, 130, 2018-03-03
Benny Thompson, 132, 2018-03-04
Benny Thompson, 138, 2018-03-05
Benny Thompson, 140, 2018-03-07
Benny Thompson, 139, 2018-03-09
Mylo Thony, 177, 2018-03-11
some of the persons are present at least, lets say 5 times. I want to create a model to predict the 5th result with regression if I give it the first four. I therefore assume that all Persons are "behaving" equally and want to transform my data into this format:
150, 155, 156, 154, 158
130, 132, 138, 140, 139
and that only for all persons who at least have 5 results in the record. I have no idea where to start, I come from the Java and C department, usually I would just run a for loop over this, but this seems very un-R-like to me, at least I have never seen anything like this yet. What is the best approach to something like this?
CodePudding user response:
As far as I understood, the following steps have to be done:
- remove rows from participants with less than 5 observations
- transfer data to wide format
Removing rows
By using the with function from base R you can remove the participants with less than 5 observations.
x <- data.frame(Name=c("Peter Parker", "Peter Parker", "Peter Parker", "Peter Parker","Peter Parker", "Benny Thompson", "Benny Thompson", "Benny Thompson", "Benny Thompson", "Benny Thompson", "Mylo Thony"),
Result=c(150,155, 156, 154, 158,130, 132, 138, 140, 139, 177))
x <- x[with(x, Name %in% names(which(table(Name)>=5))), ]
Transfer to wide format
Your data is currently in long format. It can be easily transfered to wide format using the spread function from the tidyr package.
The spread function requires a key column which contains the new column names.
If there are only 5 observations per person, you can just add a new column repeating the numbers 1 to 5 as often as there are unique values in your Name column (calculated with n_distinct from the dplyr package). Note that your data should be ordered by both Name and Date, so that the numbers are assigned to the correct observation.
x$Measurement <- rep(c(1,2,3,4,5), dplyr::n_distinct(x$Name))
x_wide <- tidyr::spread(x, Measurement, Result)
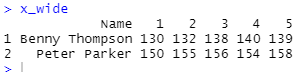
If you have more than 5 observations per person, the solution has to be modified.
CodePudding user response:
Perhaps "row" format is not the best way to perform predictions on your data. I'll give an example with dplyr/tidyr for the data in one row case:
The data:
data <- data.frame(Name = c("Peter Parker", "Peter Parker", "Peter Parker",
"Peter Parker", "Peter Parker", "Benny Thompson", "Benny Thompson",
"Benny Thompson", "Benny Thompson", "Benny Thompson", "Mylo Thony"
), Result = c(150L, 155L, 156L, 154L, 158L, 130L, 132L, 138L,
140L, 139L, 177L), Date = c(" 2018-03-03", " 2018-03-04", " 2018-03-05",
" 2018-03-06", " 2018-03-07", " 2018-03-03", " 2018-03-04", " 2018-03-05",
" 2018-03-07", " 2018-03-09", " 2018-03-11"))
data
#> Name Result Date
#> 1 Peter Parker 150 2018-03-03
#> 2 Peter Parker 155 2018-03-04
#> 3 Peter Parker 156 2018-03-05
#> 4 Peter Parker 154 2018-03-06
#> 5 Peter Parker 158 2018-03-07
#> 6 Benny Thompson 130 2018-03-03
#> 7 Benny Thompson 132 2018-03-04
#> 8 Benny Thompson 138 2018-03-05
#> 9 Benny Thompson 140 2018-03-07
#> 10 Benny Thompson 139 2018-03-09
#> 11 Mylo Thony 177 2018-03-11
To filter and transforming the data
library(dplyr)
library(tidyr)
data_in_one_row <- data |> group_by(Name) |>
mutate(count = n(), id = 1:n()) |>
filter(count == 5) |>
pivot_wider(id_cols = c(Name), names_from = id,
values_from = -c(Name, id))
data_in_one_row
#> # A tibble: 2 × 16
#> # Groups: Name [2]
#> Name Resul…¹ Resul…² Resul…³ Resul…⁴ Resul…⁵ Date_1 Date_2 Date_3 Date_4
#> <chr> <int> <int> <int> <int> <int> <chr> <chr> <chr> <chr>
#> 1 Peter Par… 150 155 156 154 158 " 201… " 201… " 201… " 201…
#> 2 Benny Tho… 130 132 138 140 139 " 201… " 201… " 201… " 201…
#> # … with 6 more variables: Date_5 <chr>, count_1 <int>, count_2 <int>,
#> # count_3 <int>, count_4 <int>, count_5 <int>, and abbreviated variable names
#> # ¹Result_1, ²Result_2, ³Result_3, ⁴Result_4, ⁵Result_5
Eventually you can apply a single linear mode prediction, depending on your expectations (on the un transformed dataset).
data <- data |> group_by(Name) |>
mutate(count = n(), id = 1:n()) |>
filter(count == 5)
model <- lm(Result ~ Name as.POSIXct(Date), data)
pred_dataset <- data |> group_by(Name) |>
summarise(Date = max(as.POSIXct(Date)) 24 * 3600)
pred_dataset$prediction = predict(model, pred_dataset)
pred_dataset
#> # A tibble: 3 × 3
#> Name Date prediction
#> <chr> <dttm> <dbl>
#> 1 Benny Thompson 2018-03-10 00:00:00 143.
#> 2 Mylo Thony 2018-03-12 00:00:00 179.
#> 3 Peter Parker 2018-03-08 00:00:00 159.