I have a dataframe like the following,
Time Value Cluster
1 2020-08-11 06:09:59 0 0
2 2020-08-11 06:14:59 0 12
3 2020-08-11 06:19:59 1 103
4 2020-08-11 06:24:59 0 0
5 2020-08-11 06:29:59 0 12
Basically there are 3 columns, the first one is date and time (Time), the second one refers to the group to which the data belongs (Cluster) and the third one (Value) is the result (in binary).
Therefore, what I would like is to be able to make a statistic according to the group that I am in this instant, the probability that the next instant the result is 1 or 0.
I have thought of the following,
- Move the result column (
Value) one position (one instant of time). - Group the data and count them.
This is the code I have made, for a single cluster,
test_df[(test_df['Cluster'] == 2)].groupby('ValueT1')['Cluster'].count()
With this out:
ValueT1
0 7406
1 7787
Name: Cluster, dtype: int64
My question is, how do you get the percentage from here? Could you make a double bar chart (one next to the other with the set of clusters)?
For the above example I would like to have as a result something similar to the following,
ValueT1
0 48.7%
1 51.2%
Name: Cluster, dtype: int64
And in addition, I would like to have a graph that gathers these percentages for each of the clusters.
Thank you very much.
CodePudding user response:
IIUC, you want to know the percentage of 0 and 1 by cluster. You can use groupby / value_counts to do that.
Setup a MRE
import pandas as pd
import numpy as np
rng = np.random.default_rng(2023)
df = pd.DataFrame({'Value': rng.choice([0, 1], 1000),
'Cluster': rng.choice(range(12), 1000)})
Output:
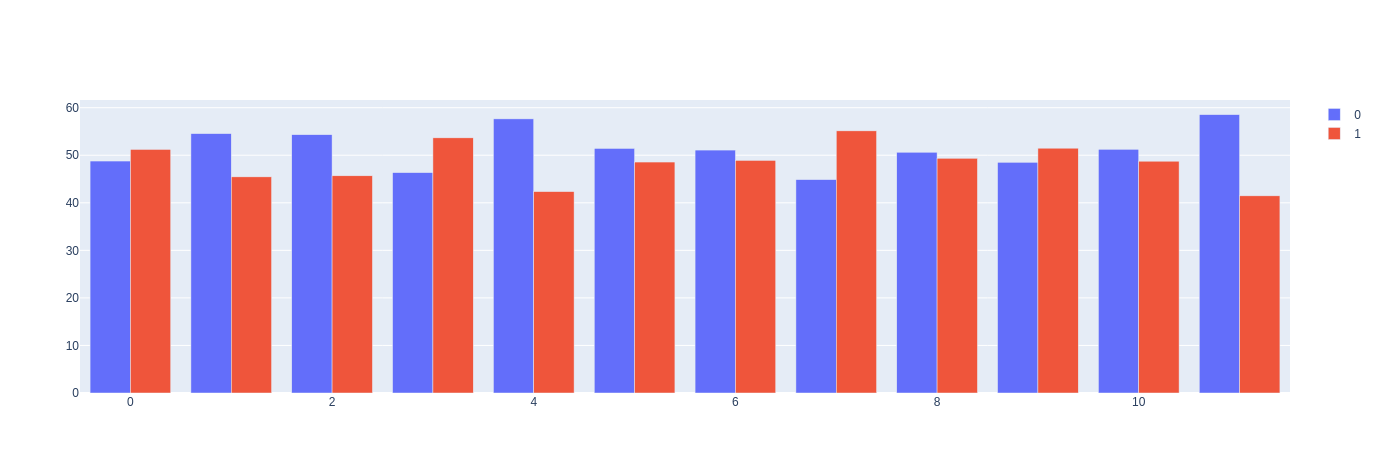
stats = df.groupby('Cluster')['Value'].value_counts(normalize=True).mul(100)
print(stats)
# Output
Cluster Value
0 1 51.219512
0 48.780488
1 0 54.545455
1 45.454545
2 0 54.320988
1 45.679012
3 1 53.658537
0 46.341463
4 0 57.647059
1 42.352941
5 0 51.428571
1 48.571429
6 0 51.086957
1 48.913043
7 1 55.128205
0 44.871795
8 0 50.632911
1 49.367089
9 1 51.485149
0 48.514851
10 0 51.250000
1 48.750000
11 0 58.536585
1 41.463415
Name: Value, dtype: float64
Update:
import plotly.graph_objects as go
stats = stats.rename('PCT').reset_index()
f1 = stats[stats['Value'] == 0]
f2 = stats[stats['Value'] == 1]
clusters = stats['Cluster'].unique()
fig = go.Figure()
fig.add_trace(go.Bar(x=clusters, y=f1['PCT'], name='0'))
fig.add_trace(go.Bar(x=clusters, y=f2['PCT'], name='1'))
fig.show()