I have a small dataframe with entries regarding motorsport balance of performance.
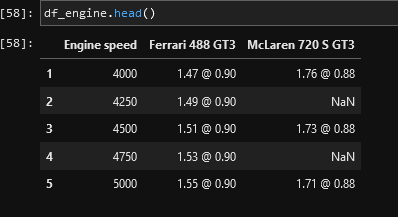
I try to get rid of the string after "@"
This is working fine with the code:
for col in df_engine.columns[1:]:
df_engine[col] = df_engine[col].str.rstrip(r"[\ \@ \d.[0-9] ]")
but is leaving last column unchanged, and I do not understand why. The Ferrari column also has a NaN entry as last position, just as additional info.
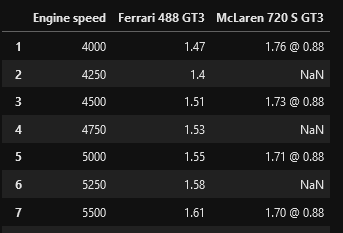
Can anyone provide some help?
Thank you in advance!
CodePudding user response:
rstrip does not work with regex. As per the documentation,
to_strip str or None, default None
Specifying the set of characters to be removed. All combinations of this set of characters will be stripped. If None then whitespaces are removed.
>>> "1.76 @ 0.88".rstrip("[\ \@ \d.[0-9] ]")
'1.76 @ 0.88'
>>> "1.76 @ 0.88".rstrip("[\ \@ \d.[0-8] ]") # It's not treated as regex, instead All combinations of characters(`[\ \@ \d.[0-8] ]`) stripped
'1.76'
You could use the replace method instead.
for col in df.columns[1:]:
df[col] = df[col].str.replace(r"\s@\s[\d\.] $", "", regex=True)
CodePudding user response:
What about str.split() ? https://pandas.pydata.org/docs/reference/api/pandas.Series.str.split.html#pandas.Series.str.split
The function splits a serie in dataframe columns (when expand=True) using the separator provided.
The following example split the serie df_engine[col] and produce a dataframe. The first column of the new dataframe contains values preceding the first separator char '@' found in the value
df_engine[col].str.split('@', expand=True)[0]