I'm trying to determine if a number in 1 column (COL A) is within a range of 2 numbers found in a nested list in another column (COL B). COL B can have several nested lists of numbers.
This is being done in Python and pandas dataframes. I'm confident I can achieve this by using for loops but I'd like to utilize a vectorized solution. My attempts at using np.where include some variation of this (I've only gone so far as to address situations where column B only has 1 embedded list of numbers. I'm guessing I could use an embedded np.where statement in the False parameter...):
test_df['inRange'] = np.where(np.isin(test_df['COL A'],list(range(test_df['COL B'][0][0],test_df['COL B'][0][1]))), 'match', 'no match')
However, I keep getting an Index Error: list index out of range I speculate I'm not using the correct syntax to refer to embedded lists from another column when using np.where.
Any insight into how to achieve what I'm attempting is appreciated. Thank you!
CodePudding user response:
You can definitely do it without loops, but I don't think it'll be much better in terms of performance when compared to a looping approach (not a whole lot of truly vectorized operations; This solution is still just looping over the rows of the dataframe and the intervals in the 2d lists, pandas just does it under the hood).
Here the trick is to use a pd.IntervalIndex, but other things are possible too.
import numpy as np
import pandas as pd
def check_in_intervals(row):
val, intervals = row
idx = pd.IntervalIndex.from_tuples(
list(map(tuple, intervals)),
closed="left"
)
return idx.contains(val).any()
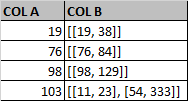
df = pd.DataFrame({
"COL A": [19, 76, 98, 103],
"COL B": [[[19, 38]], [[76, 84]], [[98, 129]], [[11, 23], [54, 333]]]
})
df["inRange"] = np.where(df.apply(check_in_intervals, axis=1), 'match', 'no match')
df:
COL A COL B inRange
0 19 [[19, 38]] match
1 76 [[76, 84]] match
2 98 [[98, 129]] match
3 103 [[11, 23], [54, 333]] match