I have a column in a DataFrame looks like this:
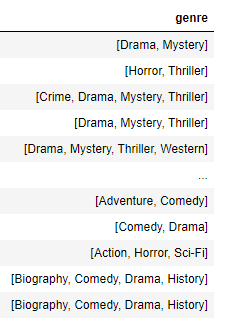
I want to count the occurrence of each value in those lists.
The output I want is a DataFrame looks like:
| Genre | Occurrence |
|---|---|
| Drama | 12224 |
| Crime | 5699 |
| Comedy | 1314 |
| ... | ... |
I've tried value_counts() and the result is the frequency of lists but the elements within them.
[Comedy, Drama] 28
[Comedy, Drama, Romance] 27
[Comedy] 25
[Action, Crime, Thriller] 22
[Crime, Drama, Thriller] 21
..
[Crime, Drama, Horror, Music, Thriller] 1
[Adventure, Drama, Romance] 1
[Drama, Romance, War] 1
[Action, Adventure, Fantasy] 1
[Action, Comedy, Horror, Mystery, Thriller] 1
I also tried to combine the column to a list of lists then count but nested for loops is not a good way. I'd love better solutions.
CodePudding user response:
you can explode and then count the values
df["genre"].explode().value_counts()
explode will spread out the contents of those lists into each row on their own, so that value_counts will count them as separate entities.