I used a GridSearchCV pipeline for training several different image classifiers in scikit-learn. In the pipeline I used two stages, scaler and classifier. The training run successfully, and this is what turned out to be the best hyper-parameter setting:
Pipeline(steps=[('scaler', MinMaxScaler()),
('classifier',
ExtraTreesClassifier(criterion='log_loss', max_depth=30,
min_samples_leaf=5, min_samples_split=7,
n_estimators=50, random_state=42))],
verbose=True)
Now I want to use this trained pipeline to test it on a lot of images. Therefore, I'm reading my test images from disk (150x150px) and store them in a hdf5 file, where each image is represented as a row vector (150*150=22500px), and all images are stacked upon each other in an np.array:
X_test.shape -> (n_imgs,22500)
Then I'm predicting the labels y_preds with
y_preds = model.predict(X_test)
So far, so good, as long as I'm only predicting some images.
But when n_imgs is growing (e.g. 1 Mio images), it doesn't fit into memory anymore. So I was googling around and found some solutions, that unfortunately didn't work.
I'm currently trying to use multiprocessing.pool.Pool. Now my problem: I want to call multiprocessing's Pool.map(), like so:
n_cores = 10
with Pool(n_cores) as pool:
results = pool.map(model.predict, X_test, chunksize=22500)
but suddenly all workers say:
without further details, no matter what chunksize I use.
So I tried to reshape X_test so that each image is represented blockwise next to each other:
X_reshaped = np.reshape(X_test,(n_imgs,150,150))
now chunksize picks out whole images, but as my model has been trained on 1x22500 arrays, not quadratic ones, I get the error:
ValueError: X_test has 150 features, but MinMaxScaler is expecting 22500 features as input.
I'd need to reshape the images back to 1x22500 before predict runs on the chunks. But I'd need a function with several inputs, which pool.map() doesn't allow (it only takes 1 argument for the given function).
So I followed Jason Brownlee's post: 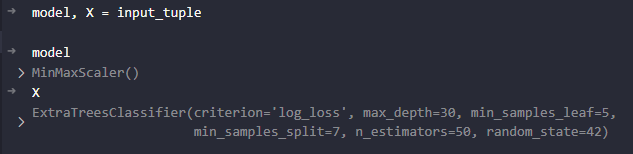
As you can see: instead of assigning model to model and X_test to X, it splits my pipeline and assigns the scaler to model and the classifier to X.